
Inteligencia artificial, data mining, machine learning, redes neuronales… Seguro que de una u otra forma han oído recientemente hablar de alguno de estos términos en relación al trading. Y es que, como contraposición de los métodos de los que hablamos en el artículo sobre Sistemas Basados en Modelos, ha aparecido en los últimos años una nueva hornada de métodos con los que a priori es posible desarrollar estrategias ganadoras sin plantear supuestos a priori sobre el comportamiento del mercado. Al contrario, los sistemas basados en minería o explotación de datos no tienen en cuenta para nada los mecanismos detrás del movimiento del precio. Por el contrario, se dedican a analizar curvas de precios u otros datos relacionados con el mercado en busca de patrones con capacidad predictiva.
Para entenderlo mejor, antes de adentrarnos en las complejidades del asunto, veamos un sencillo ejemplo: supongamos que no sé absolutamente sobre trading en los mercados. Sin embargo, tengo una herramienta capaz de detectar patrones con una determinada capacidad predictiva en cualquier conjunto de series temporales de datos. Así pues, aún sin saber nada, decido que quiero construir sistemas de trading en base a los datos típicos de una vela (apertura, máximo, mínimo, cierre) pero además también deseo que tenga en cuenta el comportamiento de una media móvil, el estocástico y el día de la semana en la que estamos.
Introducimos todos esos datos en el “caldero” (un poco más abajo veremos qué tipos de «calderos» tenemos ;)) y obtenemos un sistema que nos dicta comprar cuando el precio cierra por encima de la media móvil simple de 15 períodos, el estocástico está por encima de 50 y es martes o jueves, porque eso ha funcionado bastante bien en el 75% de las veces en el histórico.
Y lo mejor no es eso: dado que no tenemos muchas restricciones a priori (más allá de las que impongamos desde el principio, por ejemplo, que el sistema no tenga un drawdown superior al 15% o que el Profit Factor sea superior a 1) podemos generar no cientos sino miles de estrategias que en el pasado han funcionado bastante bien. El problema es que no todas serán igual válidas en el futuro (sino sería muy sencillo esto, ¿no creen?) por lo que habrá que contar con herramientas que permitan evaluar, filtrar y validar dichas estrategias. Es aquí donde entran en juego el análisis walk-forward y las simulaciones de Monte Carlo, aunque nunca tendremos garantías al 100% de que las cosas seguirán funcionando igual en el futuro. Claro que eso tampoco nos va a pasar con las estrategias basadas en modelos… Muerta la ineficiencia, muerto el sistema 😉
Dicho esto, y antes de ver los diferentes tipos de “calderos” en los que podemos introducir nuestros datos, desempolvemos rápidamente un concepto estadístico: el de regresión lineal, pues a partir de dicho concepto se desarrollan las técnicas más sofisticadas que veremos posteriormente.
Bien, ¿qué es la regresión lineal? Se trata de una técnica estadística que nos permite predecir el comportamiento de una variable y usando una combinación lineal de variables independientes, x1, x2, …., xn a través de una relación lineal de la forma:
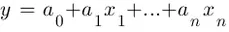
Para ello debemos calcular el valor de los coeficientes an, los cuales se obtienen minimizando la suma de las diferencias al cuadrado entre el valor verdadero de y y los valores estimados para dicha variable, es decir:
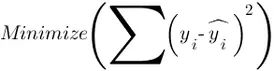
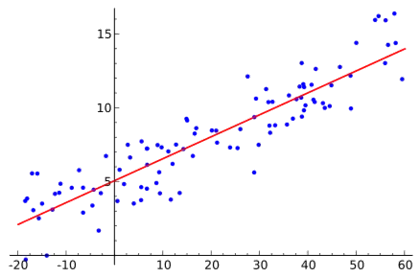
Se trataría de encontrar la recta cuya distancia a todos los puntos de datos (xi, yi) es mínima, es decir:
Por supuesto la relación no tiene que ser necesariamente lineal, pudiendo admitir otras formas (parabólica, polinomial, logarítmica, etc.) como podéis ver en el siguiente cuadro:
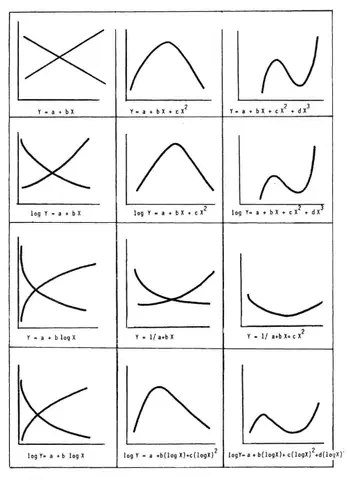
Si me han seguido hasta este punto habrán captado más o menos la idea de las técnicas que vamos a ver a continuación, pues al final de lo que se trata en todas ellas de una u otra manera va a ser de minimizar distancias, ni más ni menos. Con esa minimización podremos extraer reglas a partir de una muestra usada para entrenar al algoritmo (aprendizaje supervisado) o dejar que sea el propio algoritmo el que genere las reglas a partir de los datos sin restricciones previas (aprendizaje no supervisado). En cualquier caso, se trata de que la máquina aprenda a través de la inducción: es lo que se conoce de forma genérica como machine learning.
Dicho esto, pasemos a ver algunos de esos “calderos”.
1. Redes Neuronales
Si bien ya tocamos hace unos años este campo cuando vimos una librería dedicada a ellas en Metatrader, repasemos rápidamente qué son las redes neuronales. La idea básica de las redes neuronales es tratar de predecir un determinado resultado (output) en base a la combinación de una serie de valores de entrada o inputs. Encontrar dicha combinación con el menor error posible es lo que se conoce en el argot como “entrenar” a la red neuronal. Una vez entrenada con unos datos conocidos, el resultado se utiliza para predecir o clasificar datos no utilizados en el entrenamiento.
En Xataka tienen un artículo muy bueno en el que explican de forma muy didáctica cómo funciona una red neuronal mediante el siguiente ejemplo: supongamos que somos alumnos de una clase en la que el profesor no ha dicho exactamente cómo va a poner las notas. Lo único que sabemos es que hemos realizado dos exámenes por lo que solo disponemos de la nota de cada uno de ellos y la calificación final.
¿Cómo usamos una red neuronal para saber cuánto vale cada examen? Aquí nos bastará con la unidad fundamental de la red neuronal: el perceptrón. Un perceptrón es un elemento que tiene varias entradas con un cierto peso cada una. Si la suma de esas entradas por cada peso es mayor que un determinado número, la salida del perceptrón es un uno. Si es menor, la salida es un cero.
En nuestro ejemplo, las entradas serían las dos notas de los exámenes (n1, n2). Si la salida (nf) es uno (esto es, la suma de las notas por su peso correspondiente es mayor que cinco), es un aprobado. Si es cero, suspenso. Los pesos (w1, w2) son lo que tenemos que encontrar con el entrenamiento. En este caso, nuestro entrenamiento consistirá en empezar con dos pesos aleatorios (por ejemplo, 0.5 y 0.5, el mismo peso a cada examen) y ver qué resultado da la red neuronal para cada alumno. Si falla en algún caso, iremos ajustando los pesos poco a poco hasta que esté todo bien ajustado.
Gráficamente la cosa tendría este aspecto:
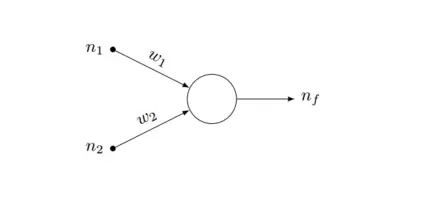
Evidentemente este es un ejemplo realmente simple. Sin embargo en la práctica la gran ventaja de las redes neuronales es que no tienen limitaciones pudiendo incorporar tantos perceptrones como deseemos, formando capas para crear lo que se conoce como redes neuronales multicapa, como la que podéis ver en el siguiente gráfico:
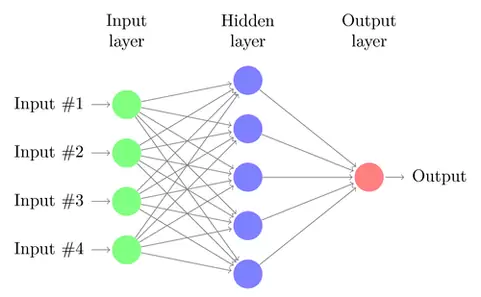
Lógicamente, cuantas más capas y perceptrones haya, más complicado será calcular los pesos y generar reglas.
Un paso más allá estarían las denominadas redes convolucionales, las cuales funcionan bastante bien a la hora de procesar datos estructurados en 2D como sería el caso de espectrogramas de señales de voz o de imágenes.
La idea de este tipo de redes es tratar de buscar características sencillas en pequeñas regiones locales en pequeños grupos de inputs (por ejemplo, en el caso de las imágenes, serían los píxeles), como pueden ser bordes o colores más o menos homogéneos. Posteriormente podemos complicarlo aún más introduciendo más capas para detectar, por ejemplo, formas circulares o cuadradas.
Su principal ventaja es que tiene menos parámetros a entrenar que una red multicapa con conexión total del mismo número de capas ocultas, por lo que su entrenamiento es más rápido; asimismo, presentan invarianza a la traslación de los patrones a identificar.
Para que se hagan una idea, actualmente este tipo de redes se usan por ejemplo para la detección y borrado automático de rostros y placas vehiculares para protección de la privacidad en Google Street View, o la detección y seguimiento de clientes en supermercados, entre otras muchas aplicaciones.
Si bien este tema a priori resulta fascinante, lo cierto es que de entrada nos vamos a tener que enfrentar con el problema de seleccionar quiénes son los inputs y cómo estructurar capas y perceptrones. Y lo malo es que, en mi experiencia, si tratamos de predecir el precio directamente usando redes neuronales seguramente obtengamos redes muy bien entrenadas pero incapaces de predecir bien utilizando datos no vistos por la red previamente. Es por ello que donde posiblemente tengan una mayor utilidad las redes neuronales dentro del trading es en la clasificación de comportamientos y patrones, una tarea esta (la de clasificar) en la que generalmente se defienden bastante bien.
No obstante, la reciente revolución en este campo que supone el advenimiento del conocido como Deep Learning o Aprendizaje Profundo, puede cambiar radicalmente el panorama de la Inteligencia Artificial y la minería de datos en los próximos años. Ahora las redes neuronales profundas utilizan múltiples capas ocultas y miles de perceptrones, que son entrenadas usando complejos algoritmos. Con ellas es posible desde realizar sistemas de recomendaciones musicales, realizar traducciones automáticas o incluso ganar al Go, juego de estrategia chino, en el que el programa AlphaGo desarrollado por Google derrotó a varios campeones de este juego.
2. Máquinas de vector soporte
Las máquinas de vector soporte o Support Vector Machines (SVMs) parten de la misma premisa que las redes neuronales: dado un conjunto de inputs, los analizamos y tratamos de generar reglas que nos permiten llegar al outputs. La novedad aquí radica en que la SVM representa los datos como puntos en el espacio, separando las diferentes clases en las que se pueden clasificar los datos mediante uno o varios hiperplanos de separación.
Para que se entienda mejor, vean el siguiente gráfico animado donde vemos una aplicación de SVM en un plano de dos dimensiones. Como podemos ver, el algoritmo de SVM va generando poco a poco la línea negra hasta que logra separar las dos clases de puntos (rojos y azules) correctamente.

Por supuesto, este ejemplo es realmente básico: en realidad podemos clasificar diferentes puntos de espacios multidimensionales, pudiendo existir varios hiperplanos y varias clases.
Tras leer esto, el lector seguramente se esté planteando qué ventajas aportan las SVMs sobre las redes neuronales: básicamente el entrenamiento de las SVMs es más eficiente, generalmente presentan menos parámetros que calcular y normalmente son capaces de alcanzar mínimos globales de distancia de separación entre los hiperplanos, mientras que en el caso de las redes neuronales podemos encontrarnos múltiples mínimos locales a la hora de entrenarlas.
A la vista de su funcionamiento, resulta incluso más evidente que en el caso de las redes neuronales que su mejor aplicación es la realización de clasificaciones. Por ejemplo podemos usar SVMs para monitorizar varios indicadores, identificar en qué condiciones el comportamiento de cada indicador se corresponde con una operación de trading potencialmente ganadora y, finalmente, estudiar cuándo todos o la mayoría de los indicadores apuntan a una operación de trading con altas probabilidades de éxito (esto también serviría para las redes neuronales).
3. K-Vecinos Más Cercanos
Al contrario que los métodos que acabamos de ver, el algoritmo de K-Vecinos Más Cercanos o K-Nearest Neighbors (KNN) no necesita entrenamiento alguno. La idea de partida en este caso es que los puntos de datos analizados son iguales o semejantes a los otros puntos que les rodean. Así, este algoritmo determina cuáles son las observaciones más próximas a la que se quiere clasificar en un espacio multidimensional, y de esa forma, decidir democráticamente como debería clasificarse la observación por la que se le pregunta.
La proximidad entre datos se mide utilizando la distancia euclídea de toda la vida, aplicando para el caso n-dimensional la siguiente fórmula:
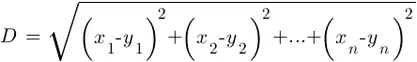
El problema aquí radica en determinar el número óptimo k de vecinos ya que, como podemos ver en la siguiente animación, la frontera de clasificación varía notablemente en función de k, no existiendo una regla definitiva para elegir su valor:
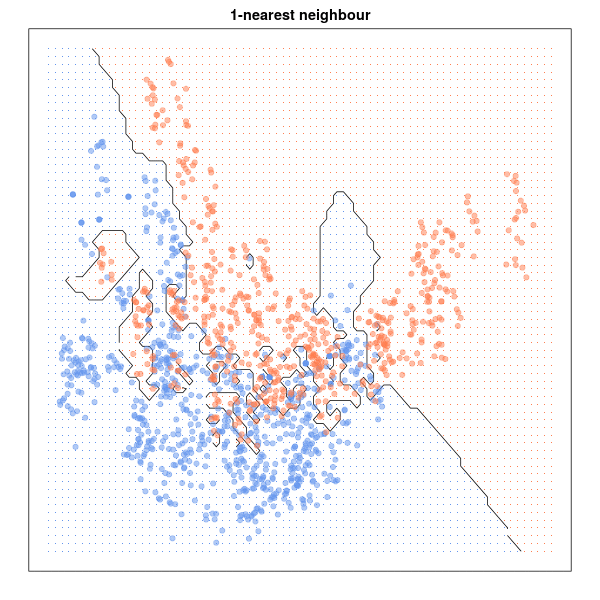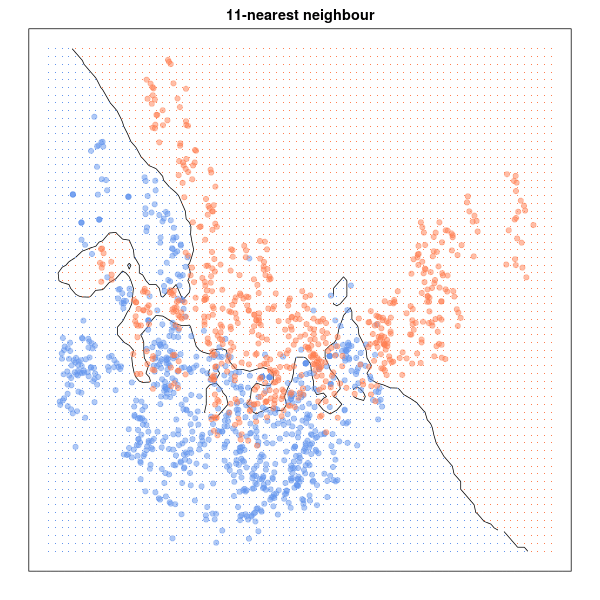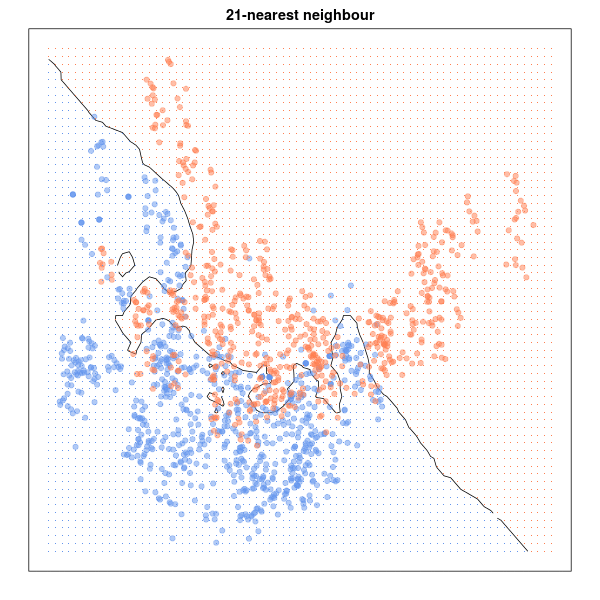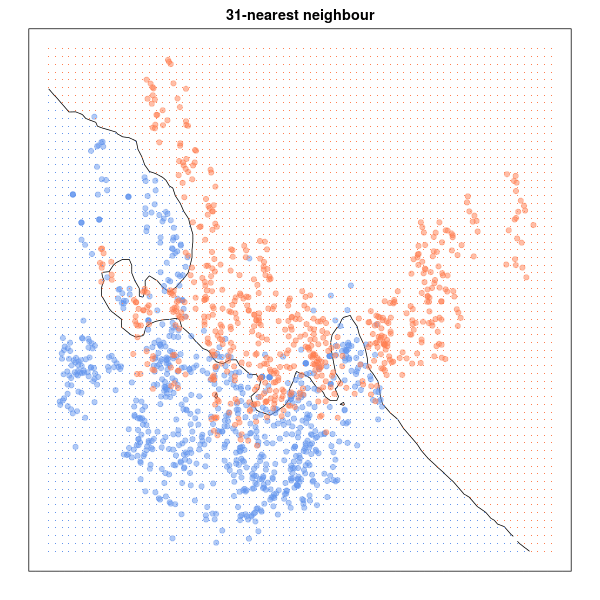
Nuevamente la utilidad de este método es la misma (es un excelente clasificador de datos) muy sencillo, fácil de entender y sin restricciones de tipo paramétrico.
4. K-Medias
El algoritmo K-Medias o K-Means presenta cierta similitud con el algoritmo anterior en el sentido de que se apoya en las distancias entre puntos para realizar clasificaciones. Sin embargo, el proceso seguido para clasificar los datos es algo más complejo: primero se parte de una semilla de datos iniciales, que establecen los grupos de partida. Seguidamente el algoritmo asigna a esos grupos todos los puntos que presenten la menor distancia a ellos. A continuación el punto utilizado como referencia para la clasificación se desplaza a la media de los grupos recién establecidos. El proceso se repite de forma recursiva de tal forma que cada vez más puntos se irán agrupando en torno a una media, la cual también se va desplazando en cada nueva iteración. El final de las iteraciones se alcanza cuando los puntos clasificados no cambian de grupo, obteniendo k tipos o clases de muestras.
Visualmente la cosa sería más o menos algo así:
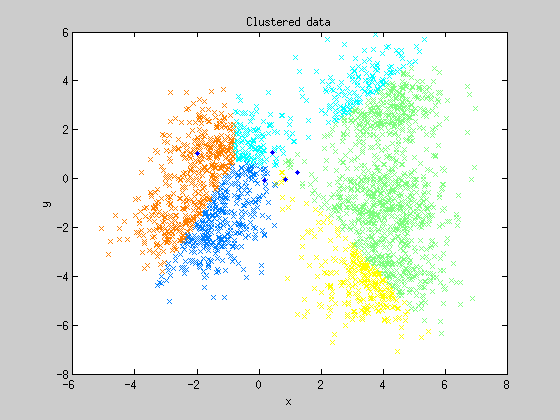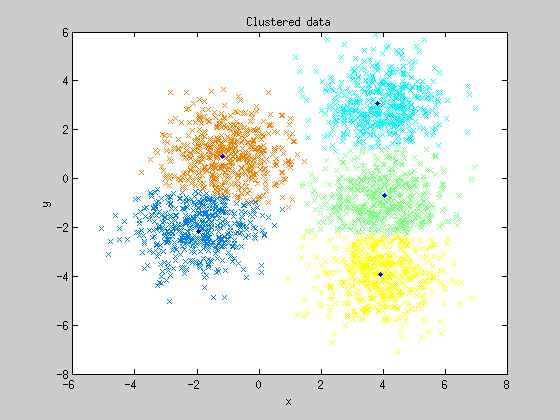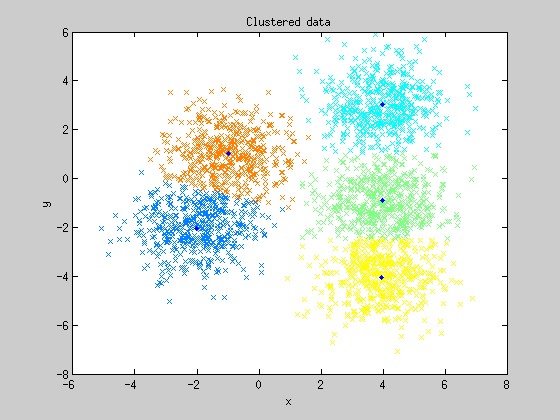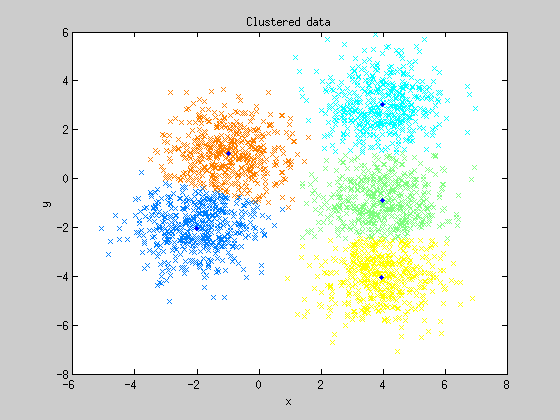
Este algoritmo tiene una aplicación muy interesante que ha desarrollado el creador de Alphadvisor, Juanma Almodóvar: seleccionar los conjuntos de parámetros óptimos de un sistema de trading. Pueden ver una explicación más detallada del asunto en los siguientes artículos de Juanma:
https://www.rankia.com/blog/juan-almodovar/1859584-como-optimizar-sistema-mediante-mineria-datos
5. Clasificador Naive Bayes
Otro algoritmo de clasificación del que se habla a menudo en esto del trading es el denominado clasificado Naïve Bayes, mediante el cual se trata de encontrar la probabilidad de que se produzca X suponiendo que Y ya se ha producido, es decir, en notación estadística P(Y || X).
Si estamos desarrollando una estrategia basada en minería de datos podemos por ejemplo preguntarnos ¿cuál es la probabilidad de que el precio suba si hoy es miércoles? Rápidamente nuestro avispado lector dirá que dicha probabilidad es el porcentaje de miércoles alcistas que existan en la muestra que analicemos, ¿verdad? ¡Meeec! Error: estamos en el mundo bayesiano, amigos, así que la probabilidad de que el precio suba condicionado a que sea miércoles se calcula como:
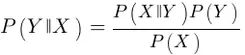
Es decir, la probabilidad de que el precio suba (Y) condicionado a que sea miércoles (X) es igual a la probabilidad de que siendo miércoles el precio suba, multiplicada por la probabilidad de que el precio suba y dividida por la probabilidad de que sea miércoles. Dicho resultado, P(Y || X), será normalmente menor que la proporción que queríamos considerar como solución a nuestra pregunta inicial, es decir, P(X || Y).
Después, para clasificar un nuevo dato que no esté presente en la muestra, no tendremos más que calcular la probabilidad de Y condicionada a diferentes eventos X para decidir qué probabilidad es mayor y clasificarlo de forma acorde. Dicha probabilidad se obtendrá como producto de las diferentes probabilidades condicionadas tal que:
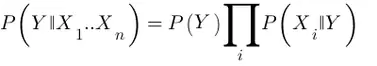
Si bien no he utilizado aún este tipo de algoritmos, presentan la ventaja de poder usar eventos cualitativos (día de la semana, datos macroeconómicos, etc.) pero a cambio nos toca suponer que los sucesos con los que trabajamos son independientes (en nuestro ejemplo, que el hecho de que hoy sea miércoles no afecte a que la semana que viene sea también miércoles), algo que no siempre sucederá debido a la presencia de persistencia y antipersistencia en ciertos datos.
6. Árboles de Decisión
Posiblemente sea una de las técnicas más populares en el campo de la minería de datos: los árboles de decisión son capaces de modelizar datos con ruido y capturar comportamientos no lineales, aparte de ser sencillos de interpretar ¿quién da más?
Los árboles de decisión permiten adoptar un enfoque top-down para analizar los datos. Para ello, podemos por ejemplo usar el valor de un indicador que nos divida la muestra de datos en dos grupos bien diferenciados. Seguidamente el algoritmo repite el proceso en cada nuevo grupo hasta que logra clasificar correctamente cada punto de datos o se alcanza un criterio de parada predefinido.
En cada punto de división, denominado nodo, se intenta maximizar la “pureza” de la cada “rama” resultante, entendida como la probabilidad de que un determinado dato caiga dentro de una determinada clase, por ejemplo subida o bajada del precio.
Podemos ver en el siguiente esquema un ejemplo de árbol de decisión que utiliza 4 indicadores (MA, EMA, MACD y RSI) para clasificar las subidas y bajadas del precio:
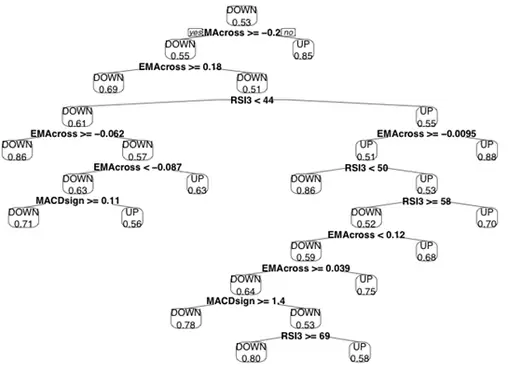
El problema que suelen presentar los árboles de decisión es que pueden sobreajustar los datos provocando que sus predicciones sean completamente erróneas al introducir datos no utilizados para la generación del árbol, un problema que suele resolverse combinado varios árboles, creando lo que se conoce como bosque aleatorio (random forest).
Conclusión
Tras escribir esta serie de artículos sobre sistemas basados en modelos y en minería de datos, llega la pregunta del millón: ¿cuál de los dos enfoques es mejor? Es evidente que la flexibilidad que proporciona la minería de datos y la eliminación de restricciones, hace que la minería de datos sea un enfoque muy atractivo para generar sistemas de trading.
Utilizando programas como StrategyQuant (por cierto, esto me recuerda que tengo pendiente hacer una review de software para generación de estrategias) podemos generar miles de estrategias ganadoras en cuestión de minutos. Sin embargo, cuando las ponemos en marcha en mercado real sin realizar ningún tipo de análisis o validación nos chocamos con la cruda realidad: nos hacen perder dinero de forma sistemática.
Es evidente que, aunque versátil y atractivo, el enfoque de la minería de datos aplicado a la generación de sistemas de trading posiblemente no sea la mejor solución ya que este tipo de técnicas no está realmente pensado para predecir, destacando más por su excelente capacidad para clasificar. Por ello es por lo que estas técnicas resultan tan útiles para mejorar sistemas que ya funcionan, por ejemplo clasificando sus parámetros en función de la robustez de sus resultados al estilo de lo que hace Juanma Almodóvar.
Y ello es así porque debemos tener en cuenta que estamos echando al “caldero” todo tipo de variables (recordemos que no tenemos una base teórica, así que cabe cualquier cosa) lo que puede terminar conduciéndonos a obtener relaciones espurias, esto es, relaciones aparentes que en realidad son ficticias por cuanto hay un tercer factor no considerado que, si fuera tenido en cuenta, invalidaría las conclusiones obtenidas. Dicho de otro modo, operar sobre la base de sistemas generados automáticamente sin una base lógica detrás que los sustente y que pueden ser el resultado de la casualidad al final conduce inevitablemente a tener pérdidas en nuestra cuenta en el momento que lo enfrentamos a datos fuera de la muestra usada para crearlos.
Espero que no me malinterpreten: no digo que no sea posible obtener estrategias válidas y consistentes usando data mining, lo que quiero decir es que lo ideal sería acotar la generación de dichas estrategias con una serie de restricciones lógicas previas. Lo ideal sería tener lo que promete StrategyQuant precisamente en su próxima versión: ser capaz de evolucionar estrategias ya existentes. Es decir, partir de la base de una idea que ya tengamos, que aparentemente tenga cierto sentido lógico, y a partir de ahí mejorarla en base a diferentes filtros y modificaciones. Posiblemente el futuro esté por ese camino, estaremos atentos a futuros progresos en esta línea.
Saludos,
X-Trader







