En el artículo anterior terminábamos exponiendo cómo una cartera equiponderada que combina los factores de retorno, value y volatilidad podía batir de forma consistente al mercado.
Este modelo se construía eligiendo las 20 primeras acciones de un ranking compuesto de los tres factores con el mismo peso. Las acciones se equiponderaban y el modelo rotaba de forma trimestral. De esta forma, las acciones elegidas eran las mejores del Russell 1000 con mejor retorno, value y volatilidad.
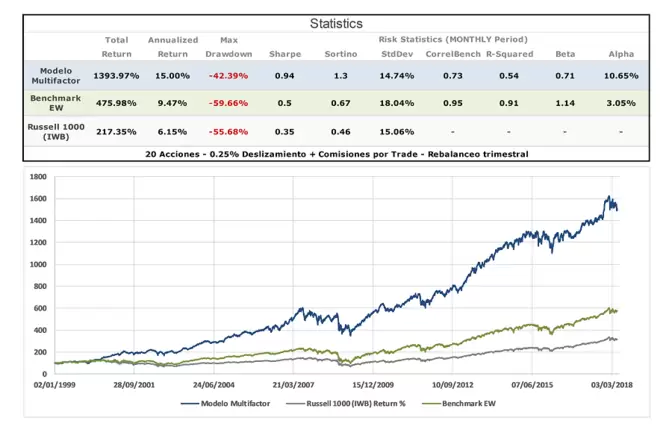
El resultado del modelo es positivo. Bate a lo largo del periodo estudiado al ETF de referencia (IWB) y a un benchmark ficticio aunque más realista que hemos construido equiponderando todas las acciones del Russell 1000 (Benchmark Equal-Weighted EW). Es lo más apropiado si vamos a utilizar una cartera también equiponderada.
Es decir, con los factores añadidos hemos ganado tanto rendimiento como disminución del riesgo. Comisiones y deslizamiento incluidos.
Pero el trabajo, obviamente, no acaba aquí. A este modelo hay que efectuarle un test de robustez y analizar en detalle los resultados.
Test de Robustez Al operar un sistema que rota la cartera cada tres meses, nos encontramos con que sólo tenemos cuatro operaciones al año. Puede que incluso la cartera apenas varíe entre rotación y rotación. Por tanto, la muestra de resultados, que tenemos desde 1999, corre el riesgo de no tener suficiente validez estadística. Puede haber sido cuestión de suerte. Además, dependiendo del periodo en el que empiece, tendré resultados diferentes. Es normal, estaré cogiendo unas acciones u otras. ¿Cómo solucionamos esto? Pues realizando lo que se conoce como rolling backtest.
Nuestras operaciones tienen una duración trimestral o, lo que es mejor, de 13 semanas. Pues el rolling backtest nos permite ver todas las operaciones teóricas del modelo que hubiera podido hacer durante estos años. Es decir, replicar todas las operaciones de 13 semanas. Así aumentamos la muestra y eliminamos el posible factor estacional. En la práctica, sólo cogerás 1/13 de todas las operaciones, pero de esta forma podemos ver si la distribución de resultados se mantiene constante y en definitiva, si es un modelo robusto. Comparamos los resultados contra el benchmark EW y contra el ETF del Russell 1000 IWB durante esas mismas 13 semanas y obtenemos lo siguiente:
Lo primero que tenemos que comprobar es, por supuesto, si ganamos. En segundo lugar, nos fijaremos en cuánto ganamos. En este caso, en 997 rotaciones obtenemos una rentabilidad media de 3,32%. Cada rotación es de 13 semanas. Los índices de referencia en este apartado obtienen un 2,42% el benchmark EW y un 1,81% el ETF IWB del Russell 1000.
Con este cálculo vemos que de media al ETF IWB le sacamos 1,51% por periodo. Cabe destacar que al benchmark EW “sólo” le ganamos 0,90% por periodo.
En ambos casos, el porcentaje de periodos que se bate al benchmark no es muy alto. De hecho, no llegan al 60% contra ninguno de los dos. Sin embargo, en ambos casos, la media de la diferencia positiva de las veces que gana es claramente superior a la media de la diferencia en los periodos que pierde respecto a los benchmarks. Es decir, gana más veces, pero no muchas más. Pero cuando gana, gana más que cuando pierde.
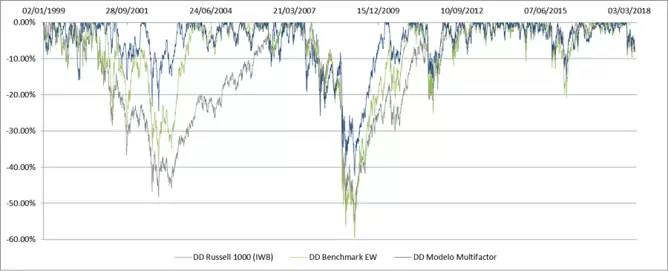
Análisis de los Drawdowns Otro elemento clave a tener en cuenta cuando se analizan sistemas son los drawdowns. Qué caídas nos podemos esperar. Para ello, mostramos en la Imagen 3 los drawdowns de las tres curvas. Puede ser difícil de ver, así que describiré qué es lo más llamativo.
Los tres sistemas alcanzan su máxima caída en el periodo de 2007-2010. Nuestro modelo tiene una caída elevada de un 42%. Pero se queda lejos de los casi 60% del benchmark EW y del más del 55% del Russell 1000 IWB. No quiero decir que un 42% sea un drawdown bajo, porque no lo es en absoluto. Pero cuando más se baja, más cuesta recuperar. Así que en este caso, y comparado con los benchmark, sí podemos decir que hemos mejorado. En fases siguientes hay que estudiar métodos para llevar este tipo de caídas por debajo del 30% o, si fuera posible, del 20%.
Otro factor positivo es que durante el periodo del 2000-2003, nuestro modelo bajó hasta casi el 25%. Mucho, pero de nuevo nada comparado con las otras curvas que llegaron a más de 40% (casi 50% el Russell 1000 IWB). Salimos ganando. Por último, hay que ver cuál es el periodo de drawdown más largo. En nuestro modelo duró algo más de dos años y medio, mientras que en el benchmark EW la recuperación del mismo periodo costó prácticamente un año más. El ETF IWB sufrió un drawdown de más de seis años después del 2000.
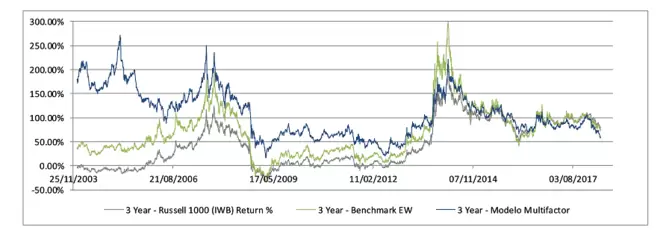
5-Years Rolling Test Ahora viene la parte más desesperanzadora del análisis: El 5-Years Rolling Test. Consiste en ver la rentabilidad que hubieras obtenido en total si hubieras estado cinco años invertido.
La gráfica muestra lo que hubieras obtenido de rentabilidad si hubieras entrado cinco años atrás, tanto para el modelo como para los benchmarks.
La parte desesperanzadora está en que aproximadamente durante un tercio del periodo (19 años de backtest menos los cinco años de inversión hacen 14 años de test) no hubiéramos batido de forma consistente a ninguno de los benchmarks. Además, ese tramo coincide con las inversiones realizadas desde 2008 en adelante.
La parte positiva es la siguiente: incluso en el tramo en el que no se bate a los benchmarks holgadamente, el modelo no pierde respecto a ellos. Es más, las tres curvas parecen seguirse muy de cerca durante ese periodo.
Este comportamiento contrasta mucho con el periodo anterior (inversiones iniciadas en 1999 hasta 2008, que sería 2004-2013 en la gráfica), donde las tres curvas están claramente separadas. Durante este periodo, el modelo bate recurrentemente a los benchmarks. De hecho, el benchmark EW bate también de forma sólida al ETF IWB del Russell 1000.
Otro punto positivo es que, a diferencia de los dos benchmarks, el “Modelo multifactor” nunca tiene un retorno negativo en cinco años. Puede ser ésta parte de la culpa por la que durante los últimos años el Modelo no haya podido despegar: la falta de caídas. Puesto que es en los periodos malos donde mejor se comporta.
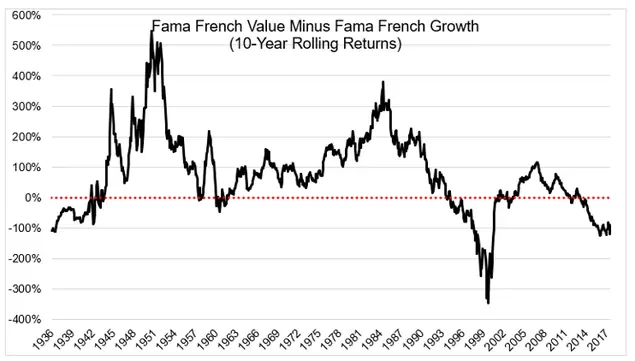
Conclusiones Hemos desarrollado un modelo basándonos en tres factores: retorno, value y volatilidad. Este modelo ha demostrado batir consistentemente a los benchmarks durante dos tercios del periodo estudiado. El tercio restante, es capaz de seguir a los benchmarks de referencia sin quedarse atrás. Cabe señalar que este periodo es uno de los más alcistas de la historia. Otro factor a tener en cuenta para este periodo es que es un periodo donde ha reinado la inversión growth sobre la value. Esto afecta directamente a nuestro modelo, en el que el factor value tiene mucho peso.
En la siguiente gráfica podemos ver la diferencia de retorno del factor value vs growth a lo largo de la historia:
¿Podríamos pensar que nuestro modelo ya no va a funcionar igual nunca? Podríamos. No obstante, sería un error desecharlo por eso. A lo largo de la historia el factor value ha funcionado de forma consistente gran parte del tiempo. En algunos tramos peor y en otros mejor. Y en otros tramos, como el periodo reciente, no ha funcionado. Si nuestro modelo es capaz de aprovecharse de esta ventaja cuando reina el factor value, pero cuando no lo hace, se mantiene estable y funciona como un índice, ¿deberíamos desecharlo?
Joel Greenblatt dijo lo siguiente:
«If I wrote a book about a strategy that worked every month, or even every year, everyone would start using it, and it would stop working. Value investing doesn’t always work. (…) And that is a very good thing.«
«Si escribo un libro sobre una estrategia que funciona cada mes, o incluso cada año, todo el mundo empezaría a utilizarla y dejaría de funcionar. La inversión value no funciona siempre. (…) Y eso es una cosa muy buena.«
Futuras Implementaciones Sin embargo, para aquellos que no se sientan cómodos pensando que un modelo (de largo plazo) puede no batir al benchmark durante años, tengo una buena noticia: se puede mejorar.
Hay muchos factores que se pueden utilizar y, además, responden a momentos diferentes del mercado. Puedes hacer un modelo que aplique timing para evitar las grandes recesiones o que en base a datos macroeconómicos aumente su exposición a unos factores u otros. Los factores también pueden estar caros o baratos e incluso tener tendencia. Y todo esto puede implementarse.
Todavía hay formas de seguir mejorando nuestro modelo.
Nota: todos los resultados mostrados son fruto de un backtest. Los rendimientos pasados no garantizan rendimientos futuros.
Artículo publicado en el número 35 de la revista Hispatrading. Regístrate en www.hispatrading.com de manera completamente gratuita para acceder a más artículos como este.