
Seguramente muchos de vosotros ya conozcáis al gran Gerard Sánchez. Asiduo a nuestras kedadas de Reus, Gerard es, aparte de una excelente persona, todo un experto en Python aplicado a finanzas cuantitativas. Recientemente ha lanzado un programa formativo denominado BQuant, en colaboración con otro grande del trading: José Suárez-Lledó, asesor del fondo de inversión Global Gradient de AndBank, gestionado con algoritmos de Machine Learning.
Con estas cartas de presentación, como os podéis imaginar no puedo hacer otra cosa que recomendaros encarecidamente dicho programa, sobre todo si estáis interesados en aprender de forma concreta y práctica sobre procesado y análisis de datos financieros para crear estrategias de trading.
Y como se suele decir en estos casos: ¡para muestra, vale un botón! Recientemente Gerard mostraba en Twitter que había «scrapeado» el Fear & Greed Index, un índice elaborado por CNN Money a partir de 7 indicadores de mercado. El problema es que el histórico de dicho índice no se encuentra disponible de forma pública para poder descargarlo e incorporarlo a una estrategia de trading. Pero dejemos que sea el propio Gerard es que nos explique cómo lo ha hecho ;).
A la Caza de los Datos
Hace algunos días descubrí Quiver Quantitative, un proveedor de datos alternativos que también permite indexarte a estrategias automáticas, todas ellas generadas con los datasets que proveen.
Como ya sabéis, soy un incansable buscador de proveedores de calidad. Me gusta mejorar los datos que ya tengo y estoy siempre al acecho de nuevos tipos y clases, porque ¡nunca sabes por dónde puede aparecer tu siguiente ventaja!
En esta ocasión vengo a documentar un reciente scraping realizado en esta web, concretamente en el apartado del índice Fear & Greed.
El Fear & Greed es una recopilación de siete indicadores diferentes que miden algún aspecto del comportamiento del mercado de valores. Dichos indicadores son el impulso del mercado, la fortaleza del precio de las acciones, la amplitud del precio de las acciones, las opciones de compra y venta, la demanda de bonos basura, la volatilidad del mercado y el diferencial entre bonos y acciones.
El índice rastrea cuánto se desvían estos indicadores individuales de sus promedios en comparación con lo que divergen normalmente. El índice otorga a cada indicador la misma ponderación al calcular una puntuación de 0 a 100, donde 100 representa la avaricia (greed) máxima y 0 indica el miedo (fear) máximo.
Scrapeando que es Gerundio
Bien, vayamos al grano. En el apartado del índice, en la web, podemos observar que el gráfico utiliza una configuración de Plotly, una librería popular de Python para hacer gráficos.
Además, si seguimos leyendo el código del front, podemos ver que efectivamente se carga otro javascript con el propio Plotly (plotly.js), así como diversas clases que contienen su nombre dentro de diversos divs.
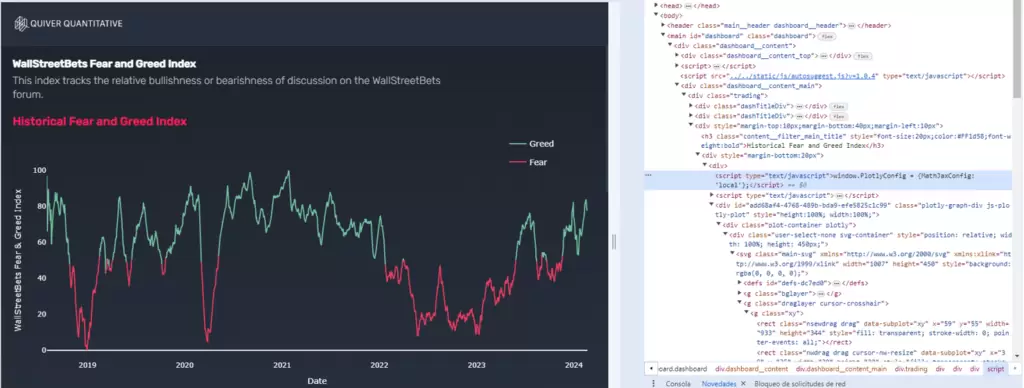
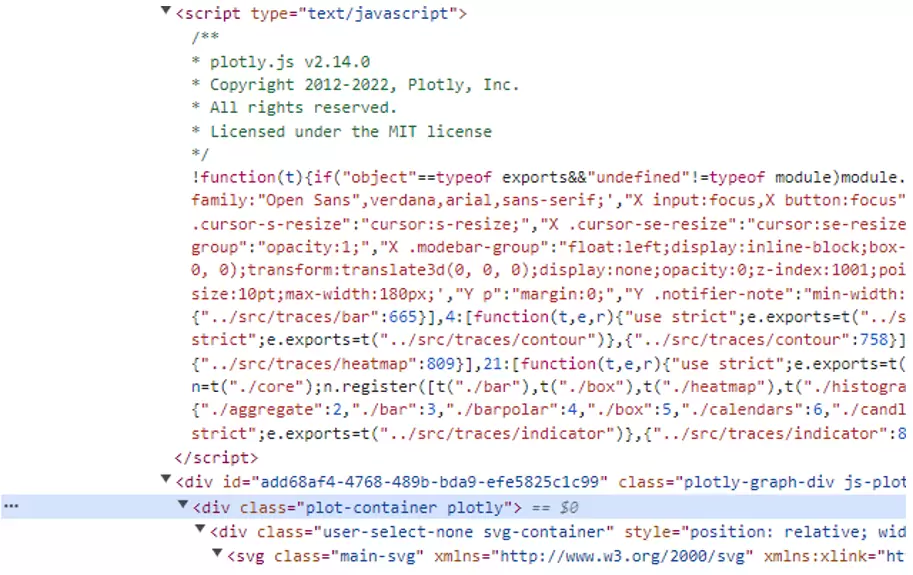
Si seguimos leyendo el código, llegaremos a otro script en el que podemos ver una serie de fechas y datos. No es difícil deducir que probablemente todo esto pertenezca al gráfico que estamos viendo, cosa que podemos confirmar con una simple comprobación.
Básicamente el código inicializa un gráfico Plotly con un objeto llamado PLOTLYENV, y los datos y fechas forman parte de la información del mismo gráfico.

Procedamos con la extracción… 😉
Cargamos las librerías que vamos a utilizar y hacemos una petición GET a la URL en cuestión con requests. Seguidamente descargaremos el contenido de la web en forma de texto y lo estructuraremos con el parser de html (descomponer en partes) de BeautifulSoup.
Buscamos el primer script que contenga “window.PLOTLYENV=window.PLOTLYENV” y lo leemos como texto.
La función re.findall se utiliza para encontrar todas las coincidencias en la cadena y extraer el contenido del grupo de captura definido por ([^]]+). Buscamos las fechas y los datos a través de las cadenas «name»: «Greed» y “name”:”Fear” para x: (fechas) y para y: (valores).
En resumen, como suele suceder en este tipo de ejercicios, se trata de hacer una limpieza del texto para quedarnos con las partes que nos interesan.
import yfinance as yf
import pandas as pd
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
import requests
html_content = requests.get("https://www.quiverquant.com/fearandgreed/").text
soup = BeautifulSoup(html_content, 'html.parser')
df = soup.find('script', text=re.compile(r'window.PLOTLYENV=window.PLOTLYENV')).text
fear_dates = re.findall(r'"name":s*"Fear".*?"x":s*[([^]]+)', df)
greed_dates = re.findall(r'"name":s*"Greed".*?"x":s*[([^]]+)', df)
fear = re.findall(r'"name":s*"Fear".*?"y":s*[([^]]+)', df)
greed = re.findall(r'"name":s*"Greed".*?"y":s*[([^]]+)', df)Ya tenemos cuatro variables con los strings de las fechas y los valores de cada etapa. Ahora vamos a transformarlos, eliminando las comillas y comas para dejarlos como fechas y números dentro de un dataframe ordenado, tanto para las fechas de Fear como para Greed.
all_values_list = [value.strip('"') for values in fear + greed for value in values.split(',')]
df = pd.DataFrame({'Values': all_values_list})
df['Values'] = pd.to_numeric(df['Values'], errors='coerce')
df['Dates'] = pd.to_datetime([date.strip('"') for dates in fear_dates + greed_dates for date in dates.split('","')])
df = df.sort_values(by='Dates').set_index('Dates')¡Ya lo tenemos todo! Ahora basta con hacer un plot del dataframe obtenido:
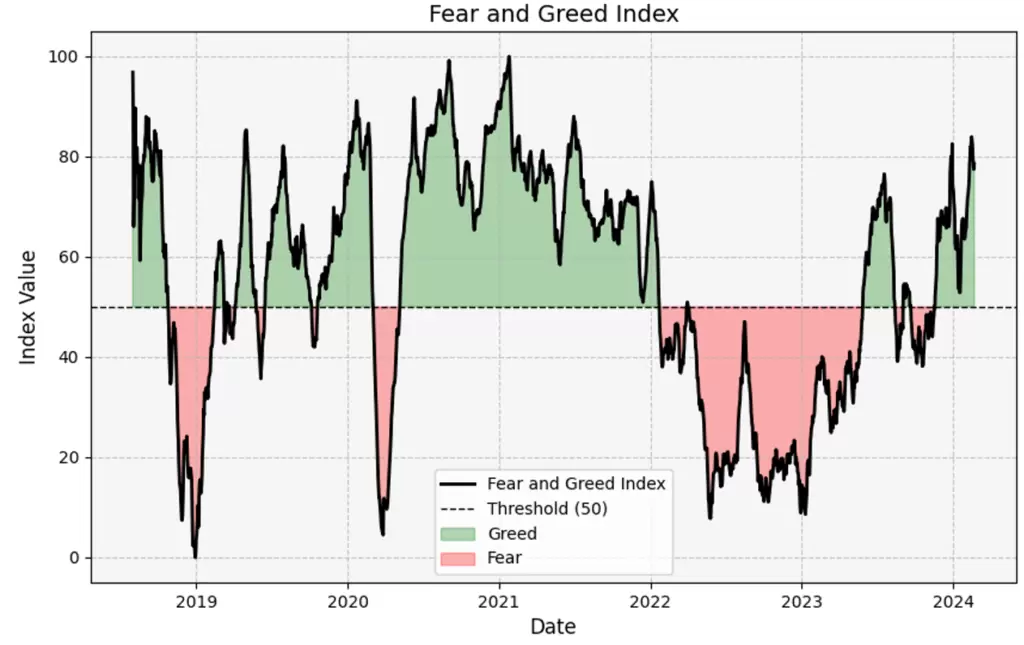
Espero que os haya gustado este sencillo tutorial de scrapeo ;). Y si queréis aprender más sobre estos temas no dudéis en pasaros por BQuant.
Un saludo,
Gerard





