Anomalías Estadísticas II: Pautas de Precio y Otras
Seguimos analizando anomalías estadísticas de los mercados, como las basadas solo en el precio u otras más curiosas como Dogs of the Dow o el efecto Super Bowl.
Seguimos analizando anomalías estadísticas de los mercados, como las basadas solo en el precio u otras más curiosas como Dogs of the Dow o el efecto Super Bowl.
En este artículo iniciamos una serie en la que examinaremos diferentes anomalías estadísticas tratadas en la literatura sobre mercados financieros.

Excelente artículo de Óscar Cagigas para la revista Traders’, donde explica cómo utilizar cadenas de Markov como base para desarrollar estrategias de trading.

Os explicamos qué es un clasificador Naive Bayes y cómo podemos usarlo para clasificar el mercado en base a los días de la semana.

En la última kedada presenté una aplicación del filtro de Kalman al trading de pares. Para los que no pudisteis asistir, aquí tenéis un resumen de mi ponencia junto con el código en R.
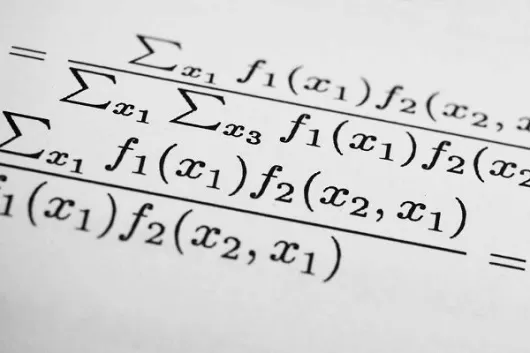
El test estadístico Z-Score nos permite determinar si los resultados de un sistema de trading son fruto de la casualidad o si realmente hemos encontrado una ineficiencia de mercado que podemos explotar.

Hispatrading comparte con nosotros un nuevo artículo de Andrés García, en el que nos explica cómo añadir ruido a los precios y usarlo para mejorar los sistemas.
Hispatrading comparte este brillante artículo de Andrés García en el que arroja más luz sobre la aplicación de las simulaciones de Montecarlo en el trading.

Retomamos la serie sobre técnicas de Machine Learning aplicadas al trading. En esta entrega veremos cómo modelizar relaciones entre variables usando la regresión con Splines.
Seguimos con la serie sobre técnicas de Machine Learning aplicadas al trading. En esta ocasión os explicamos qué es el algoritmo KNN.
Continuamos con la serie sobre técnicas de Machine Learning aplicadas al trading. En esta ocasión os explicamos cómo hacer regresiones Ridge y Lasso.
En este artículo os explicamos qué es la multicolinealidad y cómo podemos reducir el impacto negativo de la utilización repetida de la misma información.