El mundo del trading algorítmico es una búsqueda incesante de estrategias en las que se espera un posible rendimiento a futuro. Sin embargo, esta búsqueda está lejos de ser sencilla. Los desafíos que enfrentan los traders algorítmicos son numerosos y complejos. Desde la recopilación y análisis de datos hasta la implementación y optimización de estrategias, cada paso en el proceso requiere una combinación de conocimientos técnicos, rigor matemático y una profunda comprensión de los mercados financieros.
Uno de los mayores obstáculos que he observado a lo largo de mi carrera es la falta de una metodología clara y bien definida para la creación de sistemas de trading. A menudo, los traders novatos —e incluso algunos con experiencia— se encuentran atrapados en un ciclo de prueba y error, ajustando parámetros y optimizando estrategias sin un marco sólido que guíe sus decisiones. Esto no solo conduce a la frustración, sino que también aumenta el riesgo de caer en trampas comunes, como el sesgo de supervivencia y el lookahead bias, que pueden distorsionar los resultados y poner en peligro la operativa.
Ver Más Allá
A lo largo de mi carrera, he aprendido que a veces las mayores inspiraciones provienen de lugares inesperados. «Ver más allá» no es solo una expresión, sino una estrategia que me ha permitido innovar y perfeccionar mi metodología en un campo tan competitivo y técnico como el trading.
Recuerdo un día que me explicaron cómo se gestionan los procesos en el sector industrial, me di cuenta de algo que cambiaría mi enfoque para siempre.
En la industria, la selección de procedimientos no es un acto impulsivo ni basado en suposiciones. Cada procedimiento potencial pasa por una rigurosa fase de pruebas exhaustivas antes de ser implementado. No se trata solo de asegurar que funcionen bajo condiciones ideales, sino de validarlos masivamente en diferentes escenarios para verificar su consistencia y efectividad.
Este enfoque industrial me abrió los ojos a un paralelismo con lo que necesitaba en el trading algorítmico. Así nació la idea detrás de mi metodología. Al igual que en la industria, donde se prueban y validan procedimientos a gran escala, entendí que para desarrollar estrategias de trading verdaderamente robustas, debía aplicar un proceso similar.
La Importancia de Desarrollar una Buena Metodología
El «ver más allá» me permitió aplicar una perspectiva industrial a la creación de estrategias de trading, y esto ha sido fundamental para mí. Al reconocer que los principios de rigor y validación exhaustiva no son exclusivos de la ingeniería o la producción industrial, sino que pueden ser aplicados con igual éxito en el trading algorítmico, pude desarrollar una metodología propia.
Sin embargo, llegar a este punto no fue un camino sencillo. Desde el inicio, me enfrenté a un desafío crucial: no existía una metodología en el mercado que se adaptara completamente a lo que yo quería lograr. Me encontré con varias piezas de conocimiento y herramientas dispersas, cada una con su propio mérito, pero ninguna de ellas proporcionaba una solución completa.
Ante esta situación, tomé la decisión de construir algo nuevo. Comencé por recolectar y analizar diferentes técnicas y enfoques que ya existían en el ámbito del trading algorítmico, así como en otros campos. Sabía que cada uno de estos componentes tenía un valor inherente, pero también comprendí que la verdadera fuerza de una metodología reside en cómo estos elementos se integran entre sí.
Esta integración me llevó a desarrollar una metodología única, diseñada específicamente para superar los desafíos que se presentaban. No se trata solo de seguir pasos predefinidos o aplicar reglas de manera mecánica, sino de tener un enfoque estructurado que permita la creación, validación y optimización de estrategias de manera sistemática y repetible.
Metodología Probada
En el trading algorítmico, donde las decisiones se basan en datos y patrones históricos, contar con una metodología probada y testeada es fundamental. Sin una estructura clara y rigurosamente validada, cualquier estrategia corre el riesgo de fallar en el mercado real, donde la incertidumbre es la norma.
Una buena metodología no solo debe permitir el desarrollo de estrategias robustas, sino también su adaptación a nuevas condiciones de mercado. Es el marco que sostiene todo el proceso de creación y validación, garantizando que cada estrategia sea lo suficientemente flexible para evolucionar, pero lo suficientemente sólida para resistir las pruebas de robustez.
Con este enfoque en mente, me dediqué a seleccionar lo que consideré como las mejores piezas de diversas técnicas y herramientas existentes. Cada pieza que elegí se tenía que poder interconectar entre sí. Ya fuese una técnica específica de análisis de datos, un enfoque de optimización o una metodología de validación, cada componente fue cuidadosamente seleccionado por su capacidad para contribuir al ecosistema integral.
Así, al combinar estas piezas, logré construir una metodología propia que encapsula lo que, en mi opinión, es lo mejor de cada enfoque.
Primera Etapa: Rule Extraction
En el trading algorítmico, la base de cualquier estrategia robusta radica en la capacidad de identificar y seleccionar reglas que describan comportamientos del precio de manera consistente y predecible. Este proceso se conoce como «Rule Extraction» o extracción de reglas. Aunque el concepto de rule extraction no tiene un origen definido en la literatura del trading algorítmico, se ha convertido en una práctica esencial para aquellos que buscan construir estrategias basadas en minería de datos. En esencia, se trata de seleccionar patrones y comportamientos del precio que pueden ser modelados y automatizados en un sistema de trading.
La rule extraction implica analizar grandes volúmenes de datos históricos y combinar diferentes indicadores técnicos y patrones del precio para identificar reglas que puedan ser aplicadas en el mercado. Estas reglas forman la base sobre la cual se construyen las estrategias algorítmicas, permitiendo que los traders cuantitativos desarrollen sistemas que operen de manera automatizada y efectiva.
Desafíos y Soluciones en el Proceso de Rule Extraction
Cuando comencé a trabajar el desarrollo de mi metodología, me di cuenta de que el proceso de rule extraction presentaba desafíos significativos, especialmente en términos de la selección y validación de reglas. Utilizando herramientas como Python y StrategyQuant (SQX), me propuse abordar estos desafíos de manera innovadora.
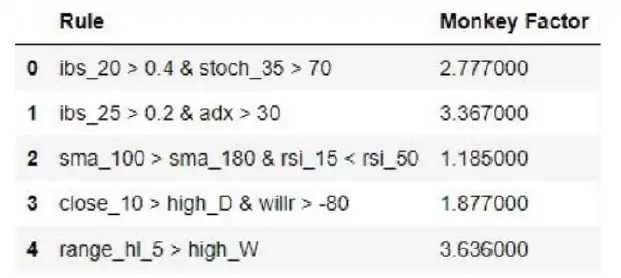
- El Reto de la Combinación de Reglas: SQX ofrece una amplia gama de posibilidades para combinar indicadores técnicos y patrones, lo que facilita la creación de estrategias complejas. Sin embargo, pronto me di cuenta de que esta flexibilidad también presentaba un problema: SQX a menudo generaba combinaciones de reglas que, en términos científicos, eran imposibles o carecían de sentido.
- Creación de Mapas Serializados en Python: Para enfrentar este problema, decidí trasladar las posibilidades de combinaciones de SQX a Python, lo que representó un reto considerable debido a la gran cantidad de combinaciones posibles. Utilicé la librería pickle de Python para crear mapas serializados que me permitieran gestionar y almacenar de manera eficiente estas combinaciones.
- Validación científica de reglas: El siguiente paso fue mejorar el proceso de generación de reglas en SQX. Para ello, desarrollé un sistema en Python que generaba posibles combinaciones de indicadores técnicos y patrones. Antes de aceptar cualquier combinación como válida, la sometía a un proceso de validación que denominé «Monkey Test», desarrollado junto a mi colega Jaume Antolí. Este test, cuyo fundamento radica en comparar el comportamiento generado contra millones de comportamientos aleatorios, aumentando la probabilidad de que las reglas propuestas tengan una base sólida.
- Mejora de la Herramienta: Este enfoque no solo resolvió el problema de las combinaciones imposibles, sino que también mejoró la herramienta en su conjunto. Al introducir un filtro basado en principios científicos, garantizaba que las reglas generadas fueran válidas y potencialmente efectivas. Esto resultó en estrategias más robustas y con una mayor probabilidad de éxito, ya que cada regla estaba fundamentada sobre una lógica sólida.
Desafío en el Desarrollo del Monkey Test
Desarrollar el Monkey Test para validar combinaciones de reglas fue un proceso que me presentó varios desafíos técnicos, especialmente en términos de rendimiento y escalabilidad.
- Transición de Java a Python: Originalmente, comencé desarrollando el Monkey Test dentro de SQX, aprovechando una parte del código open source que está escrito en Java. Para ello, reutilicé y reescribí el motor de Montecarlo de SQX para generar las pruebas aleatorias necesarias. Sin embargo, me encontré con una limitación crítica: el motor solo permitía realizar hasta 1,000 simulaciones, lo cual, para mis propósitos, resultaba insuficiente para asegurar una validación robusta.
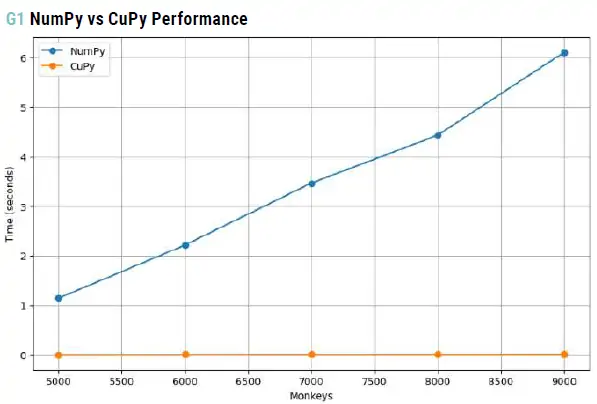
- Paso a Python y desafío de rendimiento: Para superar esta limitación, decidí trasladar el proceso completo a Python, donde tendría más control y flexibilidad. Al implementar el Monkey Test en Python, utilizando la librería NumPy para las simulaciones, noté que el cálculo de millones de pruebas aleatorias representaba un cuello de botella significativo. Las simulaciones eran extremadamente lentas cuando se ejecutaban en CPU, lo que comprometía la eficiencia del proceso.
- Solución con CuPy y rendimiento mejorado: Dado este desafío, opté por trasladar todo el cálculo a GPU usando CuPy, una librería que proporciona una interfaz similar a NumPy pero optimizada para aprovechar la potencia de las GPU. La diferencia en el rendimiento fue notable. Mientras que en CPU, utilizando NumPy, las simulaciones podían tomar varios minutos para completarse, CuPy permitió ejecutar las mismas simulaciones en una fracción del tiempo.
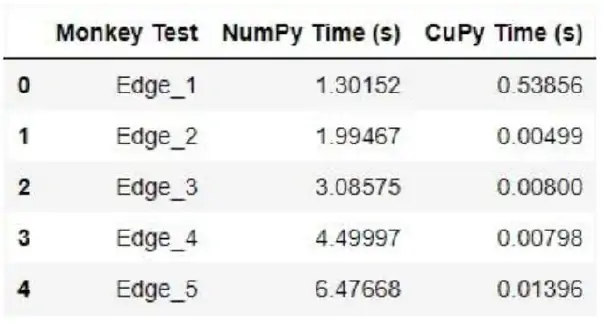
Para ser más específicos:
- NumPy (CPU): Al realizar simulaciones masivas con NumPy, los tiempos de ejecución para 1 millón de simulaciones podían ser de 15 a 30 minutos en una CPU estándar.
- CuPy (GPU): Con CuPy, al trasladar las simulaciones a una GPU moderna, los tiempos de ejecución se redujeron drásticamente, completando las mismas 1 millón de simulaciones en aproximadamente 1 a 3 minutos.
Este aumento de velocidad, fue crucial para que el Monkey Test pudiera manejar un volumen mucho mayor de simulaciones aleatorias, asegurando que las reglas fueran validadas de manera robusta y eficiente. Esta mejora no solo permitió una validación más exhaustiva, sino que también facilitó la escalabilidad del proceso, permitiendo explorar una mayor diversidad de combinaciones de reglas en un tiempo razonable.
Segunda Etapa: Refinamiento y Optimización en SQX
Una vez que el proceso de extracción de reglas en Python ha finalizado para un activo específico, comienza la siguiente fase de mi metodología. Gracias a que he desarrollado un motor en Python que se alinea perfectamente con el de StrategyQuant (SQX), puedo trasladar las reglas generadas en crudo directamente a SQX. Esta transición es crucial, ya que es en SQX donde se realiza el refinamiento, la optimización y la finalización de las estrategias.
- Paso a SQX: Las reglas extraídas por Python son pasadas en su forma más básica a SQX. En este punto, aunque las reglas ya han sido validadas y tienen un poder predictivo considerable, aún necesitan ser pulidas para asegurar su máxima eficacia. Utilizo la sección Algowizard de SQX, que es una herramienta poderosa para completar y optimizar estas reglas.
- Refinamiento del Take Profit, Stop Loss y más: En esta fase, SQX se convierte en el entorno donde puedo ajustar y perfeccionar las reglas de entrada y salida. Aunque en este punto me preocupo menos por el riesgo de overfitting (sobreajuste), ya que la regla de entrada ya ha demostrado su validez y capacidad predictiva, me enfoco en refinar otros elementos cruciales de la estrategia, como el Take Profit (TP) y el Stop Loss (SL).
El refinamiento del TP y SL es esencial, ya que estos parámetros determinan cómo se manejarán las ganancias y las pérdidas, afectando directamente la rentabilidad y el riesgo de la estrategia. Además, SQX me permite agregar comportamientos adicionales del mercado, completando así la estrategia para que se adapte mejor a las condiciones reales del mercado. - Optimización minimizando el Riesgo de Overfit: Dado que el núcleo de la estrategia (la regla de entrada) ya ha sido validado extensamente en Python, mi principal preocupación durante la optimización en SQX es mejorar la eficacia de la estrategia sin introducir riesgos innecesarios. La confianza en el poder predictivo del trigger de entrada me permite utilizar las capacidades de SQX para explorar ajustes y optimizaciones adicionales, sabiendo que, en principio, la base de la estrategia es sólida.
Al final de este proceso, lo que comenzó como una regla cruda extraída por Python se transforma en una estrategia refinada y optimizada, lista para ser ejecutada.
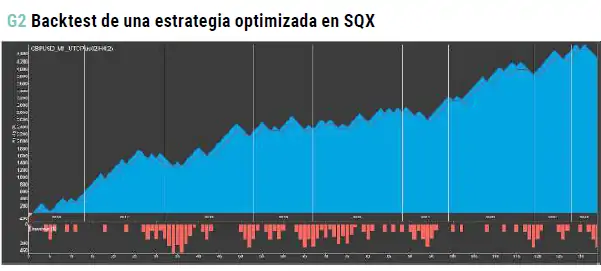
Tercera Etapa: Validación Masiva con la Metodología SV3
La fase final de mi metodología es quizás la más crucial: la validación. Aquí es donde todas las estrategias que han pasado por las etapas anteriores se someten a pruebas rigurosas para determinar su eficacia y robustez.
Para ello, he adaptado la metodología SV3, desarrollada por Marcos López de Prado, a mi propio proceso, lo que me permite validar no solo estrategias individuales, sino un conjunto masivo de estrategias, proporcionando una visión cuantitativa de la eficacia de mi metodología en su conjunto.
¿Qué es la Metodología SV3?
SV3 es una técnica de validación basada en la idea de dejar una parte de los datos fuera del proceso de construcción de la estrategia, reservándolos para el final del todo. Esta técnica permite evaluar cómo se comporta la estrategia con datos que no han sido vistos durante su desarrollo, lo que es crucial para evitar el sobreajuste (overfitting). Básicamente, SV3 divide los datos en tres partes: entrenamiento, validación y un conjunto final que solo se utiliza para la validación definitiva, garantizando que el rendimiento observado no es un producto del azar o del ajuste excesivo a los datos históricos.
- Adaptación del SV3 en mi Metodología: He tomado este concepto y lo he adaptado para aplicarlo a todas las estrategias que surgen de las fases anteriores de mi metodología. Después de que las reglas son extraídas y refinadas en SQX, las estrategias pasan a esta fase final de validación utilizando el enfoque SV3. En lugar de aplicar SV3 a una sola estrategia, lo hago de manera masiva, validando simultáneamente todas las estrategias que han sido generadas. Este enfoque no solo me ayuda a cuantificar cuán efectiva ha sido mi metodología en general, sino que también me da una mayor confianza en los resultados obtenidos, ya que no se basa en el rendimiento de una sola estrategia, sino en un conjunto amplio de ellas.
- Validación a Gran Escala: El verdadero poder de esta fase radica en la validación masiva. Mientras que validar una sola estrategia podría proporcionar una visión limitada y potencialmente engañosa de su eficacia, al aplicar SV3 a cientos de estrategias, puedo obtener un panorama mucho más fiable y completo de la robustez de mi metodología. Esto es comparable a la validación masiva de procesos en la industria, donde no se confía en el rendimiento de una sola máquina o proceso, sino en la capacidad de todo el sistema para operar de manera eficiente bajo diversas condiciones.
- Importancia de la Validación Masiva: Esta última etapa es fundamental porque me permite
evaluar no solo la calidad de las estrategias individuales, sino también la eficacia de toda la metodología que he desarrollado. Si un gran número de estrategias pasa con éxito esta fase de validación, puedo estar seguro de que la metodología en su conjunto está bien diseñada. Además, al validar masivamente, minimizo el riesgo de confiar en resultados aislados que podrían ser simplemente productos del azar.
En resumen, la validación masiva utilizando la metodología SV3 me proporciona una seguridad adicional en la calidad de las estrategias que he desarrollado. Es una etapa que, aunque compleja, es esencial para asegurar que las estrategias que llegan al mercado no solo sean teóricamente sólidas, sino también prácticas y lo más robustas posibles en un entorno real.
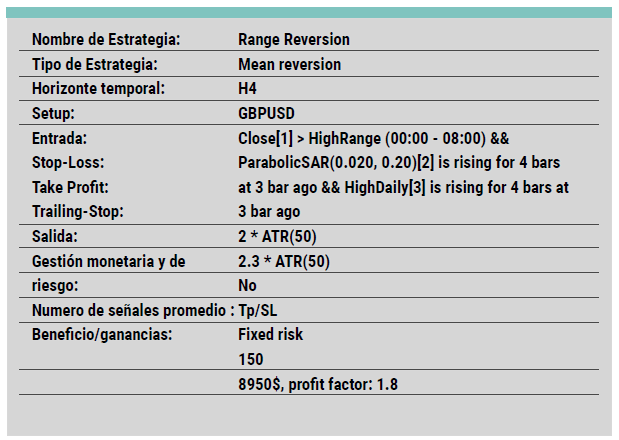
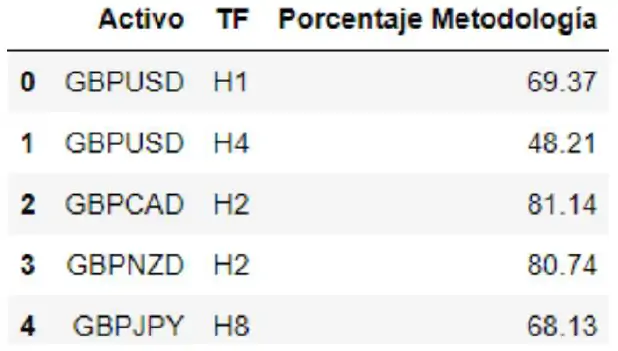
La Importancia de un Enfoque Propio en el Trading Algorítmico
Más allá de las técnicas y herramientas específicas que he utilizado, hay una lección fundamental que quiero destacar: la importancia de desarrollar un enfoque propio.
En el mundo del trading algorítmico, no existen pasos claramente definidos o un manual universal que garantice el éxito. Cada trader debe encontrar su camino, explorando, experimentando y adaptando las metodologías a su propio estilo y necesidades. En mi caso, fue la integración de principios de otros sectores, la adaptación de herramientas existentes, y la creación de procesos combinados lo que me permitió construir una metodología propia.
Considero que el verdadero valor en el trading algorítmico radica en la capacidad de innovar y de personalizar el enfoque según las propias fortalezas y objetivos.
Esto implica no solo dominar las herramientas disponibles, sino también ser crítico y creativo en su aplicación, ajustándolas para superar los desafíos específicos que se presentan en cada etapa del desarrollo de estrategias.
Al final del día, el éxito en el trading algorítmico no proviene de seguir un conjunto rígido de reglas preestablecidas, sino de la habilidad para desarrollar un enfoque propio, basado en la observación, el análisis, y la validación.
Este enfoque es lo que, bajo mi punto de vista, marca la diferencia entre una estrategia pasajera y un sistema de trading duradero y efectivo.
Sobre el Autor
Alan Tomillero Martínez es desarrollador profesional, especialista en análisis de datos y machine learning, y ganador de Robotrader 2024. Es inversor y colaborador en proyectos de trading algorítmico y criptomonedas. Podéis contactarle en atomillerom[a]gmail.com
Artículo publicado en el número de octubre de 2024 de la revista TRADERS’. Regístrate en www.traders-mag.es de manera completamente gratuita para acceder a más artículos como este.







