---
title: Python Para Traders. Primeros Pasos
date: 2023-03-15T15:33:36Z
modified: 2024-07-05T16:10:08Z
permalink: "https://www.x-trader.net/python-para-traders-primeros-pasos/"
type: post
status: publish
excerpt: ¿Pensando en transformar tu operativa e iniciarte en el trading cuantitativo? Aquí tienes una guía para iniciarte en este campo programando en Python.
wpid: 11057
categories:
- Sistemas de Trading
tags:
- Python para Trading
- Trading Cuantitativo
featured_image: "https://www.x-trader.net/wp-content/uploads/2023/03/Python-Trading-Quant.jpg"
featured_image_alt: Python-Trading-Quant
author: X-Trader
---
Seguro que más de alguno de vosotros ha pensado en **transformar su trading e iniciarse en esto del trading cuantitativo**, para lo cual seguro que os habéis encontrado con una importante barrera de entrada: **toca aprender a programar**. Y además no en cualquier lenguaje, sino en uno muy específico: **Python** (que, por cierto, se lee “paizon” en inglés).
Para todos aquellos que se encuentren en esta tesitura, y a pesar de que yo soy más fan de R (por cierto, tenéis aquí una [serie de artículos](https://www.x-trader.net/tag/r-para-traders/) sobre este lenguaje), os he preparado esta **breve guía introductoria** para que podáis dar **vuestros primeros pasos** y cacharrear con datos financieros usando el lenguaje de la pitón :D.
Dicho esto, ¡vamos al lío!
## Qué Es Eso de Python
Python es un lenguaje interpretado, dinámico y orientado a objetos creado a finales de los años ochenta por **Guido van Rossum** del Centrum Wiskunde & Informatica (CWI) holandés. El nombre de este lenguaje proviene de la **afición de su creador** por los humoristas británicos **Monty Python**.
El espíritu de este lenguaje es el de conseguir que la programación sea **más accesible para la gente** y así **aumentar el nivel de ‘alfabetización’** básico en lenguajes de programación.
Sin embargo, la cantidad de proyectos y funcionalidades disponibles en Python **ha evolucionado de tal forma en los últimos diez años**, que ha terminado por convertirse en el lenguaje preferido para cualquier cosa relacionada con **ciencia de datos y machine learning**, siendo el **lenguaje más demandado** en LinkedIn, por encima de Java o C++.
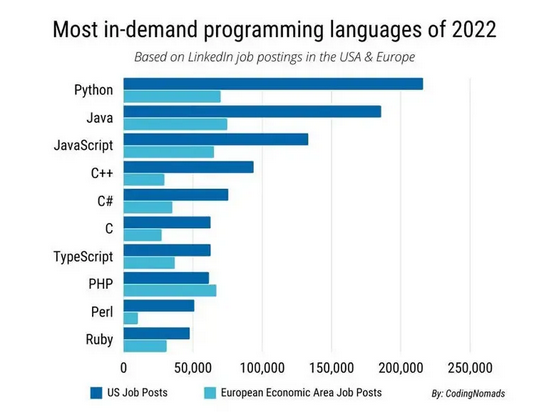
Dicho de otro modo: tanto si queréis hacer vuestros primeros pinitos en el análisis de series financieras como dedicaros de forma profesional al trading cuantitativo, **no queda más remedio que pasar por Python**, por cuanto casi todo lo que necesitéis estará seguramente ya implementado en este lenguaje. Pensad que en [PyPi](https://pypi.org/), el repositorio de paquetes para Python, ahora mismo tenéis **más de 400.000 paquetes disponibles**, de los cuales hay varios miles dedicados a finanzas, inversión e inteligencia artificial.
## Los Diferentes Sabores de la Pitón
Dicho esto, seguramente el **primer problema** al que os enfrentéis cuando decidáis adentraros en el mundo de Python es que **hay muchas formas de trabajar con este lenguaje**, usando diferentes entornos de desarrollo o [Integrated Development Environments (IDEs)](https://wiki.python.org/moin/IntegratedDevelopmentEnvironments).
Así, podemos trabajar directamente a pelo con su línea de comandos pero también podemos usar **entornos más visuales** como [PyCharm](https://www.jetbrains.com/pycharm/), [Wing](https://wingware.com/) o el propio [Visual Studio](https://visualstudio.microsoft.com/es/vs/features/python/) de Microsoft. Incluso si necesitáis **compartir código y resultados** con otros usuarios, tenemos los denominados notebooks que facilitan enormemente esta tarea, como es el caso de [Jupyter Notebook](https://jupyter.org/) o [Google Colab](https://colab.research.google.com/).
Sin embargo, si estáis pensando en empezar a trabajar con un entorno completo a la par que intuitivo, **os recomiendo que empecéis con Anaconda**, gratuito y que podéis descargar desde [https://www.anaconda.com](https://www.anaconda.com).
Entre otras **ventajas** de este entorno, tenemos las siguientes:
- Trae un **montón de paquetes preinstalados** como Pandas o NumPy, fundamentales para trabajar con datos.
- Además viene con **Jupyter Notebook** que, para que nos entendamos, es como un cuaderno web donde ir guardando los avances que vayamos realizando con nuestro código, y que además podemos compartir fácilmente con otros usuarios.
- Incluye un **gestor de entornos integrado** denominado **Conda**. Con él podemos instalar, ejecutar y actualizar rápidamente los paquetes que deseemos así como sus dependencias.
- Permite **configurar y utilizar entornos virtuales fácilmente**. Para aquellos que no sepan de que se trata, un entorno virtual son una suerte de “cajones” que nos permiten mantener y gestionar proyectos separados entre sí. De este modo, podemos usar una versión distinta de Python o usar diferentes paquetes en diferentes proyectos.
- Su interfaz **Anaconda Navigator** es **intuitiva** y **basada en web**, eliminando la necesidad de tener que utilizar la línea de comandos para gestionar nuestros paquetes.
El tutorial que pasamos a ver a continuación está hecho sobre este entorno, así que os recomiendo que, antes de seguir, os **instaléis la versión correspondiente** a vuestro sistema operativo para que podáis ir siguiendo los pasos.
## Jugando con la Anaconda
Una vez instalado Anaconda (ya os adelanto que tarda un poco) y realizadas las primeras operaciones para terminar de configurarse, os encontraréis con una ventana como esta:
Lo primero que deberemos hacer para estar un poco más cómodos es configurar nuestro propio entorno virtual. Para ello, deberemos acudir al menú **Environments** que aparece a la izquierda y darle a **Create**:
Le ponemos un nombre, marcamos Python (por cierto, aquí también podemos coger R) y elegimos la versión que vamos a usar:
Una vez pulsemos en el botón **Create**, Anaconda construirá el entorno e instalará algunos paquetes base. Sin embargo, en ese listado veréis que **no tenemos nada relacionado con finanzas**, así que es **hora de instalar** algunos paquetes interesantes en nuestro nuevo entorno.
Para ello, pinchamos en el desplegable que aparece en la parte superior y marcamos **All**. Seguidamente, para asegurarnos de que tenemos el índice de paquetes actualizado, le damos al botón **Update Index…**
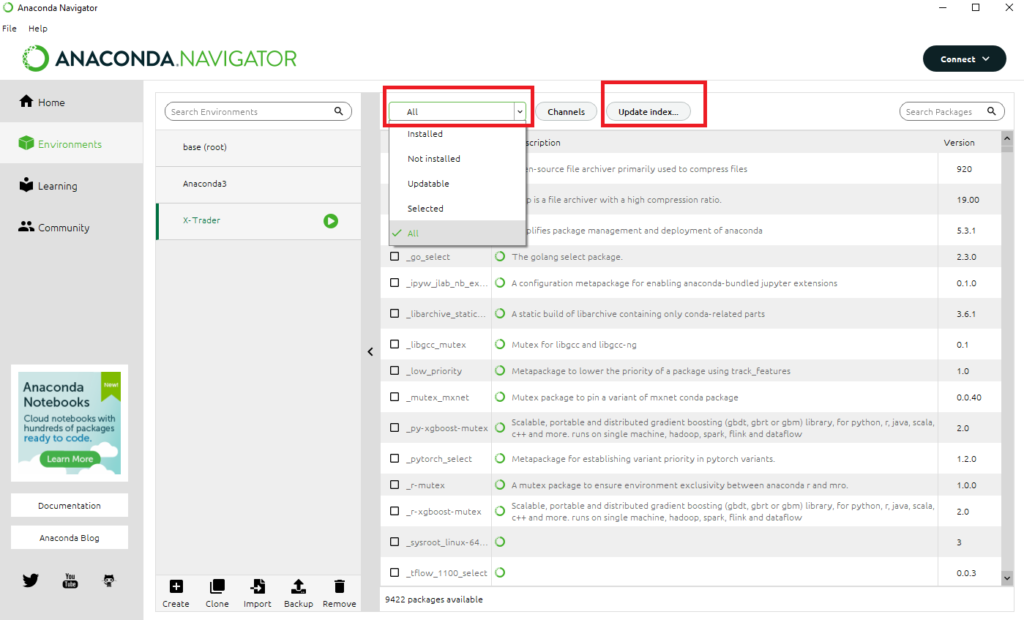
Seguidamente en el cuadro de búsqueda de la derecha, tecleamos **Pandas**. Marcamos el paquete del mismo nombre en la lista que nos aparece y pulsamos en **Apply** (nos pedirá que instalemos también algunas dependencias):
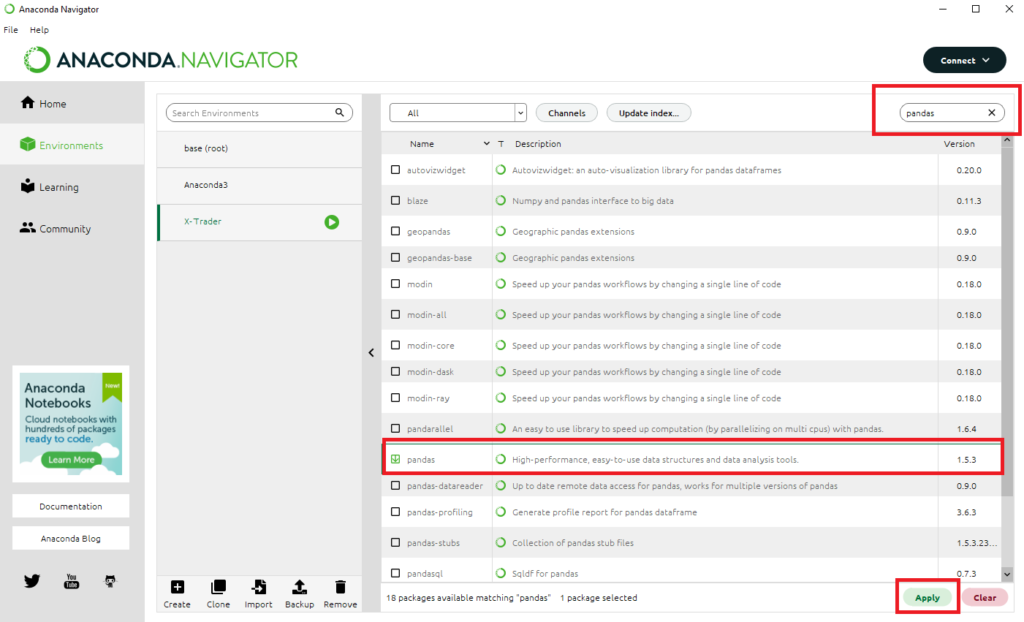
Con esto acabamos de instalar el paquete [Pandas](https://pandas.pydata.org/docs/index.html), el cual es posiblemente **la librería más popular en Python** por cuanto contiene todas las funciones necesarias para cargar datos, procesarlos, manipularlos, analizarlos y modelizarlos. Vamos, **un todo en uno**, obligatorio para cualquier trader quant que se precie.
Importante: **como deberes** os dejo **instalar el paquete [Matplotlib](https://matplotlib.org/)** (los pasos son idénticos, solo cambia el nombre), ya que lo necesitaremos más adelante para elaborar gráficos.
## ¡Queremos Datos!
Un poco de paciencia je je, ahora vamos con eso. De entrada si queréis cargar datos propios que tengáis en CSV, no tenéis más que usar el clásico[ pandas.read\_csv](https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html), pero si no tenemos datos propios, podemos trabajar, por ejemplo, con los de **Yahoo Finance!**, para lo cual podemos usar el paquete **YFinance**, con el que podremos descargarlos fácilmente.
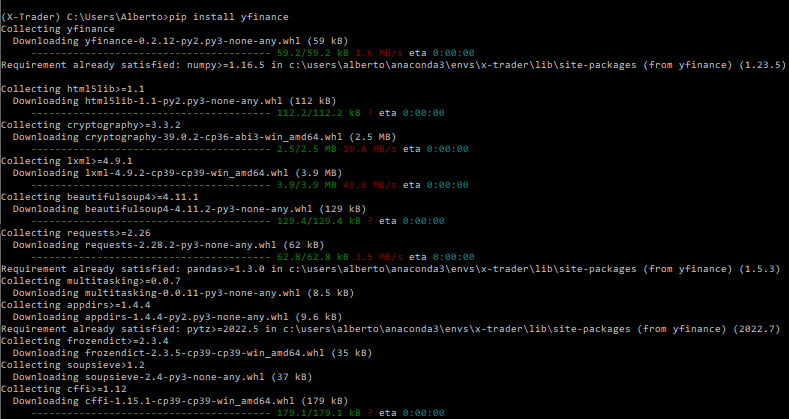
Sin embargo, tenemos un pequeño problema con este paquete: no está en el índice de paquetes de Anaconda. Pero no pasa nada: aprovechando este pequeño contratiempo, os voy a enseñar a usar **Pip** (no, nada que ver con el mercado Forex :D).
**Pip** (acrónimo de Package Installer for Python) es una herramienta que **simplifica la instalación de paquetes Python** desde la línea de comandos y que vamos a usar para instalar el paquete YFinance.
Para ello, deberemos hacer click en el pequeño botón verde con el símbolo de **Play** que aparece junto al nombre de nuestro entorno y seleccionamos **Open Terminal**.
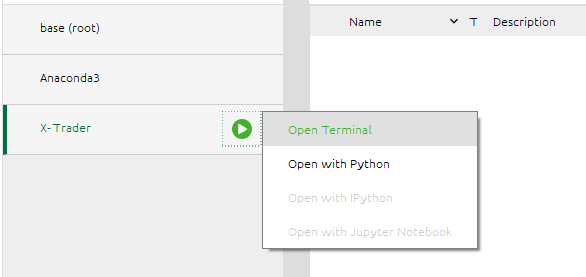
En la ventana de terminal que nos aparecerá, escribiremos:
```
pip install yfinance
```
Pulsamos Enter y, si todo va bien, aparecerán muchas líneas de texto indicando que se está realizando la instalación del paquete y de sus dependencias.
## Nos Vamos a Jupyter
Ahora que ya tenemos Pandas, Matplotlib e YFinance instalados en nuestro entorno, vamos a crear nuestro primer cuaderno de trabajo con Jupyter Notebook para hacer nuestros primeros pinitos con los datos.
Para ello, cerramos la ventana de terminal anterior y volvemos a la pantalla inicial de Anaconda. Comprobamos que en la parte superior está seleccionado nuestro entorno, buscamos entre los iconos del Navigator el de **Jupyter Notebook** y hacemos click en **Install**:

Una vez instalado, el botón que ponía Install debería poner ahora **Launch**. Hacemos click en él y se nos abrirá una pestaña dentro de nuestro navegador web con el siguiente aspecto:
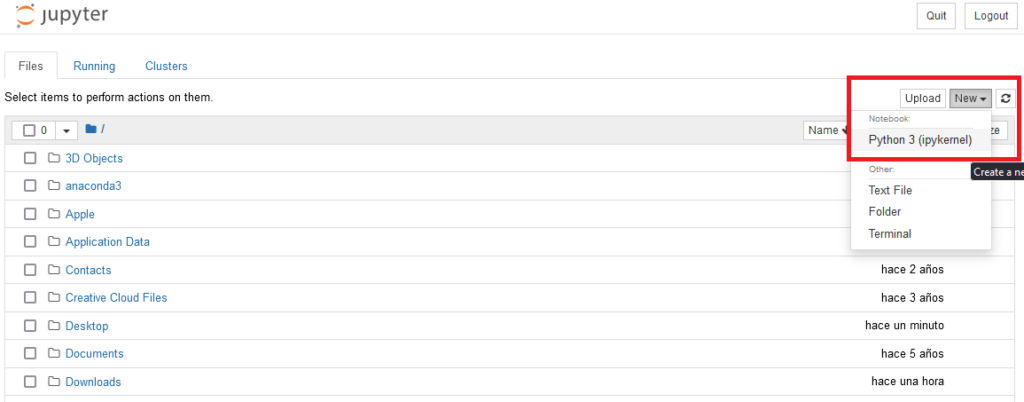
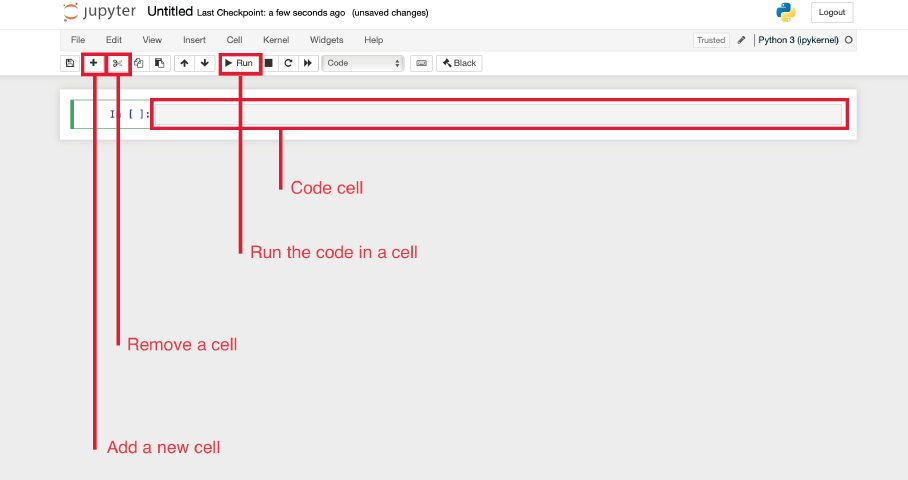
Para crear nuestro primer notebook, hacemos click en **New** y seleccionamos “**Python 3 (ipykernal)**”. Se nos abrirá una nueva pestaña con el navegador con algo similar a esto (os he añadido algunas **referencias** de lo que hace cada apartado del menú):
Ahora que estamos en todo lo alto, es el momento de descargarse el histórico completo de alguna serie bursátil con tan solo 3 líneas de código. Fijaos: en la primera celda escribimos lo siguiente para **importar yfinance y matplotlib**:
```
import yfinance as yf
import matplotlib.pyplot as plt
```
Seguidamente nos bajamos el **histórico completo de cotizaciones de JP Morgan** hasta ayer mismo:
```
data = yf.download("JPM", start="1980-03-17", end="2023-03-14")
```
Y seguidamente escribimos data para ver el contenido descargado:
```
data
```
Si pulsamos en el botón **Run** que aparece en el menú superior, el resultado debería ser el siguiente:
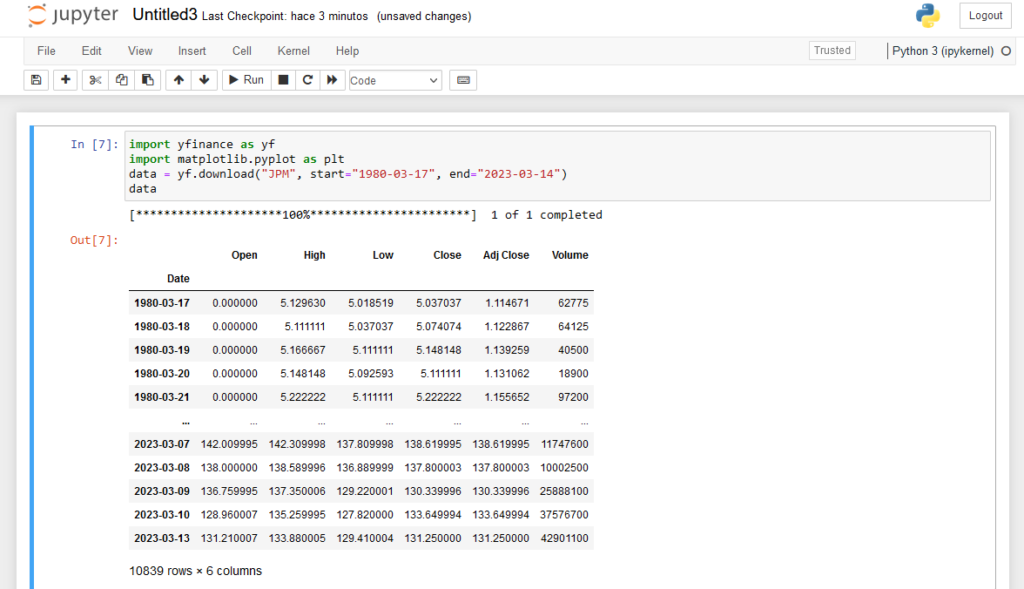
El formato de datos de Data es el de un **dataframe de Pandas**, esto es, una estructura de datos de doble entrada compuesta de filas y columnas, que posteriormente podremos usar con las funciones de otros muchos paquetes.
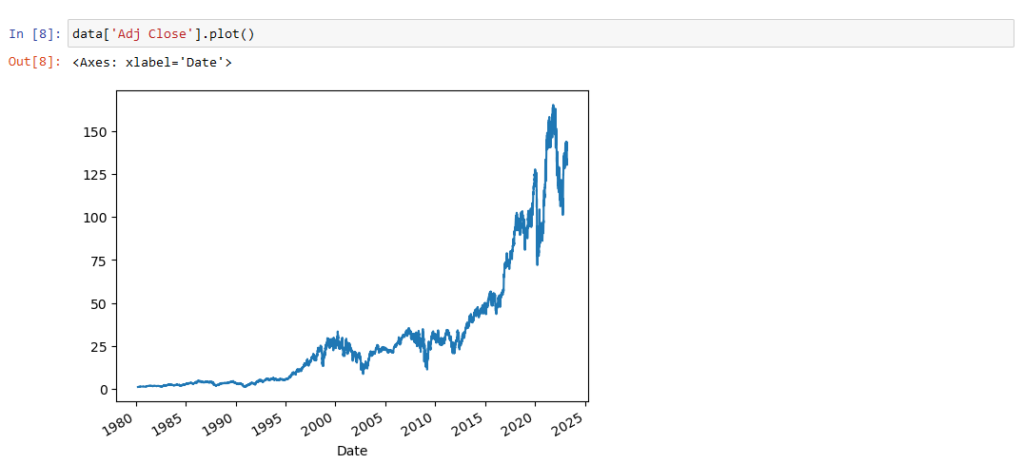
Vamos a jugar ahora con los datos descargados. Por ejemplo, extraigamos la columna de cierres ajustados y **dibujémosla** sin más que añadir plot() al final:
```
data['Adj Close'].plot()
```
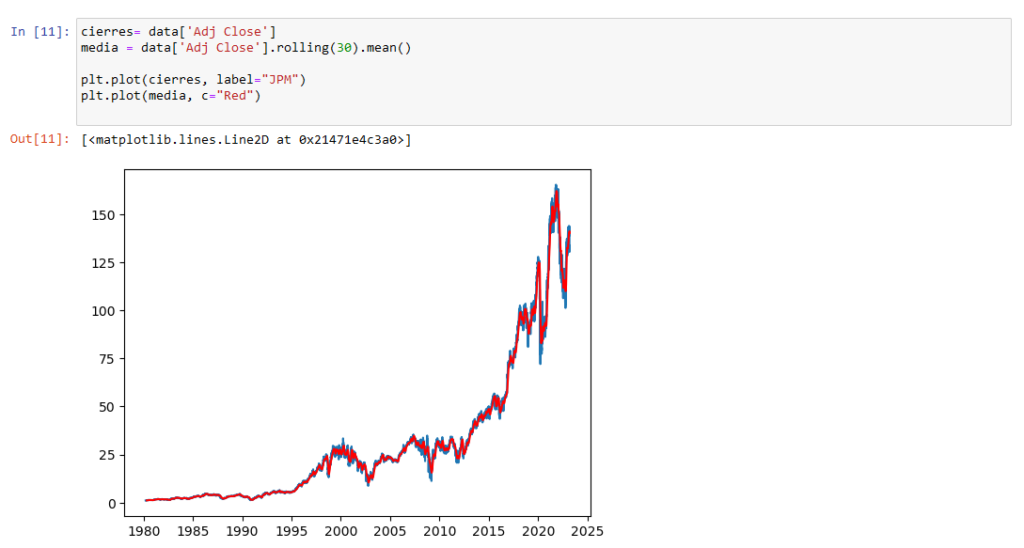
¿Y qué tal meterle una **media móvil simple de 30 sesiones** y superponer los dos gráficos?
```
cierres= data['Adj Close']
media = data['Adj Close'].rolling(30).mean()
plt.plot(cierres, label="JPM")
plt.plot(media, c=”Red”)
```
## Dibújame un Sistema de Trading
¡Pues claro que sí, para eso hemos llegado hasta aquí! Para ello, vamos a investigar una conocida pauta de las Bolsas: el [**efecto fin de mes**](https://www.x-trader.net/anomalias-estadisticas-i-pautas-estacionales/) que, como seguramente recordaréis, lo que nos indica es que los mercados suelen presentar un **marcado sesgo bajista en los últimos días del mes**, y un **comportamiento claramente alcista en los primeros días de mes**.
Comenzamos realizando la **importación de las librerías** que utilizaremos (no os preocupéis por instalar Numpy, ya viene por defecto):
```
%matplotlib inline
import pandas as pd
import numpy as np
import yfinance as yf
```
Para nuestro análisis, vamos a descargar los **datos del SPY**, esto es, el ETF sobre S&P 500. Dado que queremos usar todo el histórico, no incluimos fechas.
```
spy = yf.download("SPY")
```
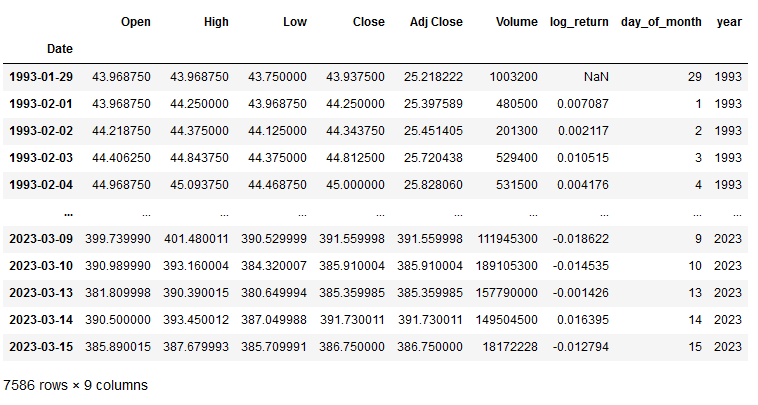
A continuación, añadimos al dataframe una columna con los **rendimientos logarítmicos** de la serie de cierres ajustados:
```
spy["log_return"] = np.log(spy['Adj Close'] / spy['Adj Close'].shift(1))
Seguidamente añadimos otra columna con el día del mes y otra con el día del año:
spy["day_of_month"] = spy.index.day
spy["year"] = spy.index.year
spy
```
Si hemos hecho todo bien hasta aquí, el resultado del dataframe sería este:
Graficamos ahora el resultado **agrupando rendimientos por día del calendario**:
```
grouped_by_day.plot.bar(title="Rendimiento Promedio por Día de Calendario")
```
El resultado que se obtiene es el siguiente:
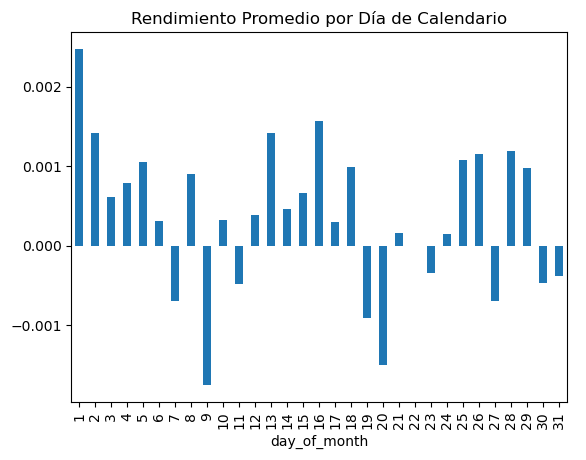
En el gráfico anterior podemos ver claramente como, **en los primeros días del mes, se produce un fuerte repunte alcista, si bien las bajadas a final de mes no son tan marcadas como cabría esperar**, por lo que convendría tomar diferentes partes del histórico para ver si en algún momento el efecto ha sido más pronunciado.
Con esta información, vamos a crear una **estrategia de trading** cuya regla operativa será muy sencilla: **comprar y mantener SPY durante la primera semana del mes**. Para ello, añadimos al dataframe una columna con los **rendimientos de dicha semana**:
```
spy["first_week_returns"] = 0.0
spy.loc[spy.day_of_month <= 7, "first_week_returns"] = spy[spy.day_of_month <= 7].log_return
```
Calculamos el rendimiento promedio por año de comprar y mantener en la primera semana y lo graficamos:
```
spy.groupby("year").first_week_returns.mean().plot.bar(title="Rendimiento Promedio de la Estrategia por Año")
```
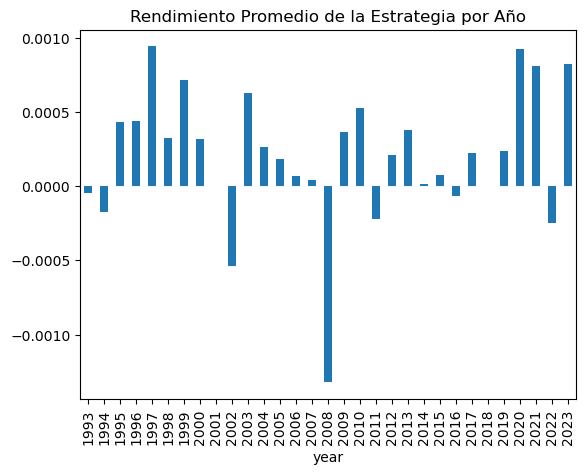
Podemos ver en el gráfico anterior como, a excepción de muy pocos años (generalmente bajistas, como es el caso de 2008), la estrategia **obtiene en media resultados positivos** anualmente.
Examinemos ahora el rendimiento acumulado de la estrategia:
```
spy.groupby("year").first_week_returns.sum().cumsum().plot(title="Rendimiento Acumulado de la Strategia por Año")
```
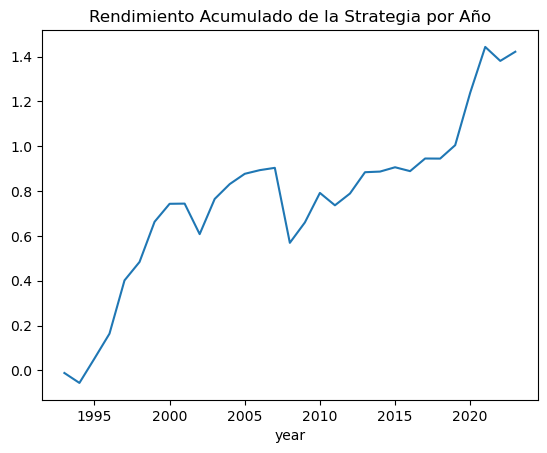
¡Muy interesante! Nuestro sistema de trading basado en el efecto fin de mes tomando solo la pata alcista de la pauta resulta ser **ganador**, generando un **40% sin reinvertir capital** en los últimos 30 años.
## Conclusión
En este artículo hemos realizado una **introducción al entorno de Python** y a su uso para **cargar y analizar datos** de forma sencilla. También hemos aprendido a **usar Jupyter Notebook** para guardar los resultados de nuestros experimentos y, de paso, hemos creado un **sistema de trading muy sencillo**, basado en una conocida pauta estacional, que además ha resueltado ser ganador.
En próximos artículos, **profundizaremos** algo más en el uso de Python para desarrollar **sistemas de trading más avanzados** y cómo obtener y analizar sus correspondientes **métricas**.
Ah y por si queréis trastear con los Notebooks de ejemplo que hemos visto, os los dejo en un zip que podéis descargar desde [este hilo del Foro](https://www.x-trader.net/foro/viewtopic.php?t=21584).
Saludos,
X-Trader
## Topics
**Categorías:** [Sistemas de Trading](https://www.x-trader.net/wp-content/uploads/wp-mfa-exports/taxonomy/category/sistemas-de-trading.md)
**Etiquetas:** [Python para Trading](https://www.x-trader.net/wp-content/uploads/wp-mfa-exports/taxonomy/post_tag/python-para-trading.md), [Trading Cuantitativo](https://www.x-trader.net/wp-content/uploads/wp-mfa-exports/taxonomy/post_tag/trading-cuantitativo.md)