Antes de iniciar este artículo explicando el código utilizado para extraer pautas estacionales usando Python, quisiera agradecer a unos excelentes profesionales como son Antonio Rodríguez (Paduel), Alex Ríos, Valentin Morala (Tiotino) y Jesús por sus citas referentes al tema, ya que me sirvieron y mucho para crear el algoritmo.
Introducción
¿Alguna vez te has preguntado si puedes operar un sistema en base al análisis cuantitativo (es decir, en base a los tópicos matemáticos y estadísticos que este obedece)? Para situar la cuestión, hagamos un brainstorming de posibles cuestiones sobre el tema:
Si existe ventaja estadística con el Trading Estacional, ¿qué ratios jugarían a mi favor y en contra? ¿Cuánto es el DD promedio y el máximo DD que tiene un recorrido específico en día, semana o mes? ¿Cuánto es el DD máximo que ha producido el activo? ¿Cuánto es el retorno promedio por día, semana y mes? ¿Cuánto es el rango medio diario negativo, RDN? ¿Cuánto es el rango medio diario positivo, RDP? ¿Cuánto es la ratio RDN/RDP? ¿Cuál es la tasa de crecimiento anual compuesto? ¿Qué % conlleva hacer Buy & Hold. ¿Cuánto es la máxima pérdida diaria? ¿Cuánto es la mínima pérdida diaria? ¿Qué ratio de Sharpe me arroja las diversas combinaciones grupales diarias, semanales o mensuales? Por ejemplo, Sharpe del grupo de los primeros 10 días del mes o del grupo de los días 21 al 30 de cada mes.
¿Cuánto es la volatilidad anualizada del activo? Volatilidad mínima (¿Cuándo fué?) Volatilidad máxima (¿Cuándo fué) ¿Cuál es el VaR en sus diferentes escalas? ¿Cuánto es la desviación típica? ¿Cuánto es la desviación típica por día, semana y mes?
¿Qué distribución de retornos presenta el activo? ¿Cuál es su coeficiente de asimetría? ¿Cuál es su curtosis? ¿Cómo de constante es su media?
En este artículo trataremos de dar respuesta a muchas de estas cuestiones, por supuesto en forma de código.
Algunos Scripts para Realizar Análisis Cuantitativo de una Serie Financiera
Para realizar un análisis cuantitativo de de una serie financiera por días, semanas y meses, vamos a aplicar diferentes bloques de código que he programado en Python, aplicándolos al Vanguard Consumer Staples ETF (VDC) en el período comprendido entre el 01-02-2004 y el 31-05-2022. Los pasos a seguir son los siguientes:
# Importamos las librerías
import statistics
import pandas as pd
import yfinance as yf
import numpy as np
from datetime import date
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
# %matplotlib inline
pylab.rcParams["figure.figsize"] = 20, 10
plt.style.use("ggplot")
# Escogemos activo y delimitamos las fechas de inicio y final
symbol_data_yahoo = "VDC"
inicio_data = "2004-02-01"
today = date.today()
fin_data = "2022-05-31"
symbol_fecha ="nVanguard Consumer Staples Index Fund ETF Sharesn2004-02:2022-05"
# Etiquetamos los diferentes plots
caso_volatilidad = ("Seasonality Trading {}nEvolución histórica del precio y la volatilidad".format(symbol_fecha))
caso_retornos_acumulados = ("Seasonality Trading {}nRetornos acumulados-Drawdown".format(symbol_fecha))
caso_heatmap_principal = ("Seasonality Trading {}nRetornos medios diarios por mes, Retornos promedios mensualesnDesviación Estándar".format(symbol_fecha))
caso_distribucion = ("Seasonality Trading {}nDistribución Histórica de Retornos Diarios".format(symbol_fecha))
caso_roc_general = ("Seasonality Trading {}nROCS diarios de cada mes".format(symbol_fecha))
caso_roc_individual = ("Seasonality Trading {}nROCS diarios de cada mes".format(symbol_fecha))
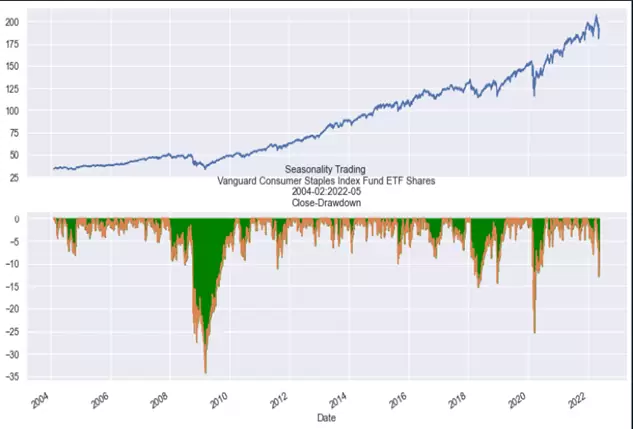
caso_drawdown = ("Seasonality Trading {}nClose-Drawdown".format(symbol_fecha))
caso_roc_segmentado = ("Seasonality Trading {}nROCS & Drawdow segmentado".format(symbol_fecha))
caso_boxplot = (format(symbol_fecha))
# Declaramos las variables y descargamos la data en bruto
ticker = symbol_data_yahoo
start_date = inicio_data
end_date = fin_data
data = yf.download(ticker, start = start_date, end = end_date)
# Modelamos la data
def ajustado(df):
df=df.copy()
lista=['Open','High','Low']
for f in lista:
df[f]=df[f]*df['Adj Close']/df['Close']
df=df.drop('Close', axis=1)
df=df.rename(columns = {'Adj Close': 'Close'} )
return df
data = ajustado(data)
# Eliminamos los NAs y visualizamos la data en el explorador de variables
df=data
df.head()
df.describe()
df.isnull().sum() #Contamos los NAs
df = df.dropna(how="any") #Eliminamos los NAs
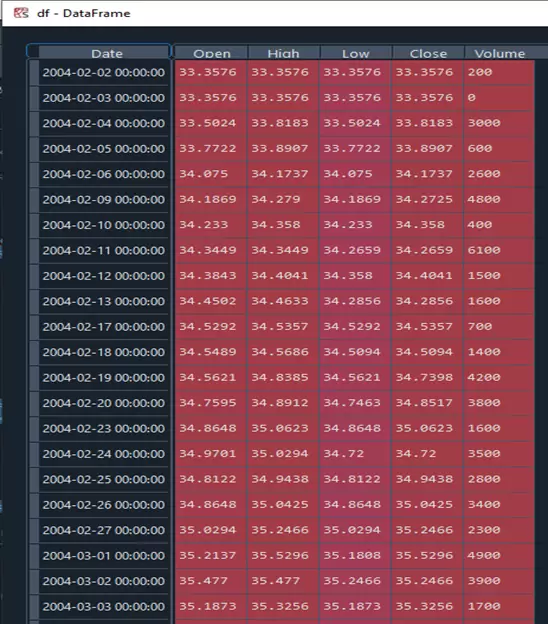
df
Si hemos hecho todo correctamente, el dataframe resultante será el siguiente:
A continuación pasamos a realizar un primer test para ver como de constante es la media de los rendimientos porcentuales de la serie. Para ello, aplicamos un t-test, que nos sirve para ver si una media es distinta de cero para una distribución dada. Si nuestra media es distinta de cero, al menos, podemos decir que al menos tenemos la posibilidad de ganar dinero.
Para nuestro caso particular, el cálculo del estadístico utilizado en el t-test es bastante sencillo: simplemente debemos obtener el cociente entre la media del proceso y su desviación típica corregida por la raíz cuadrada del número de sucesos (en todo caso, por si tenéis curiosidad podéis encontrar toda la teoría y las variantes de este conocido test estadístico así como algunos ejemplos en estos apuntes de la UC3M).
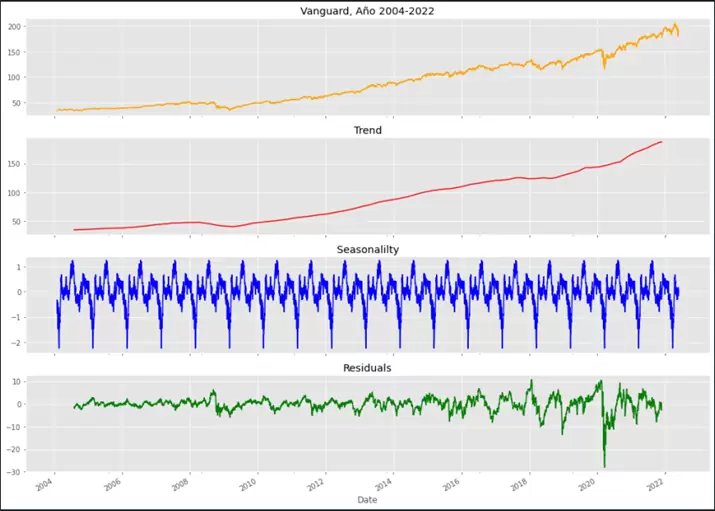
Pasamos a continuación a realizar la descomposición estacional de la serie de cierres y graficar el resultado obtenido. Para ello, utilizaremos la librería statsmodels de la siguiente manera:
Pasamos a representar gráficamente la información anterior. Por ejemplo, podemos representar la evolución del ETF vs los drawdowns históricos que ha tenido usando el siguiente código:
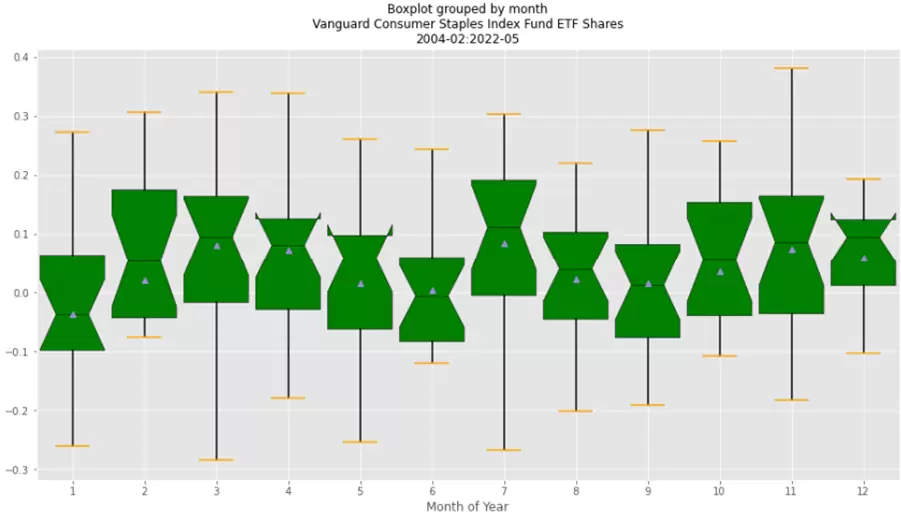
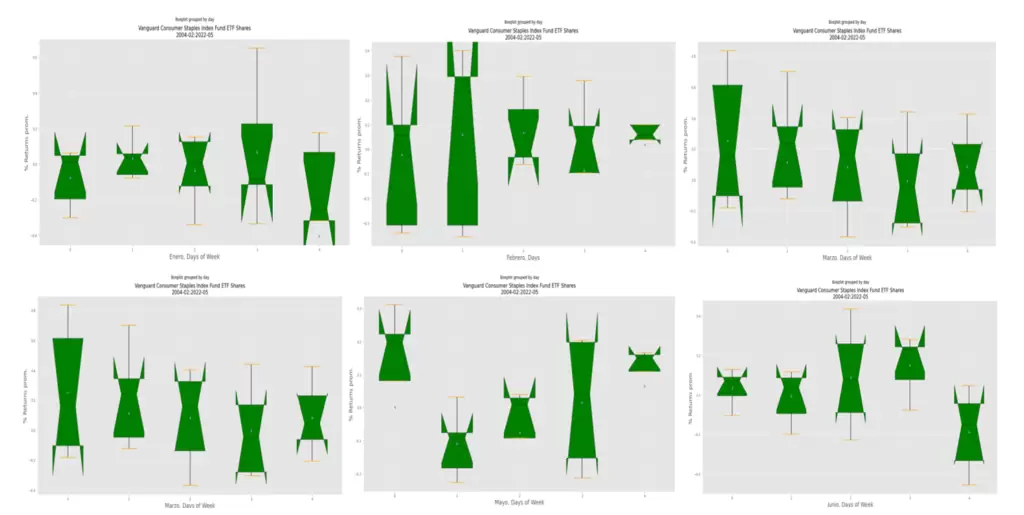
Con esta información podemos elaborar algunos boxplots muy interesantes agrupando los rendimientos promedio de diferentes maneras. Por ejemplo, utilizando el siguiente código podemos analizarlos para cada mes del año:
Como podemos ver, no se observan grandes variaciones, estando febrero, marzo, abril, julio, octubre, noviembre y diciembre por encima del 0,5% de rendimiento promedio.
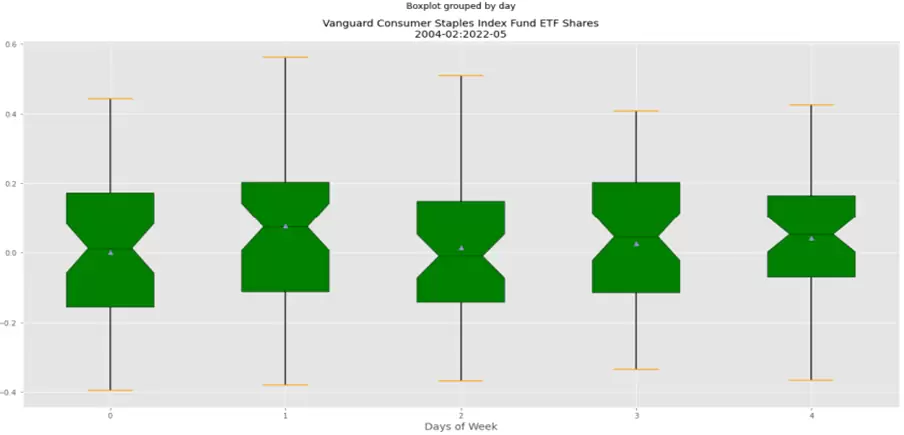
¿Qué tal si ahora observamos la variación de los retornos de los días de la semana? Esto os lo dejo como ejercicio, pero el gráfico que debéis obtener sería el siguiente (recordad que en Python, Lunes=0 y Viernes=4):
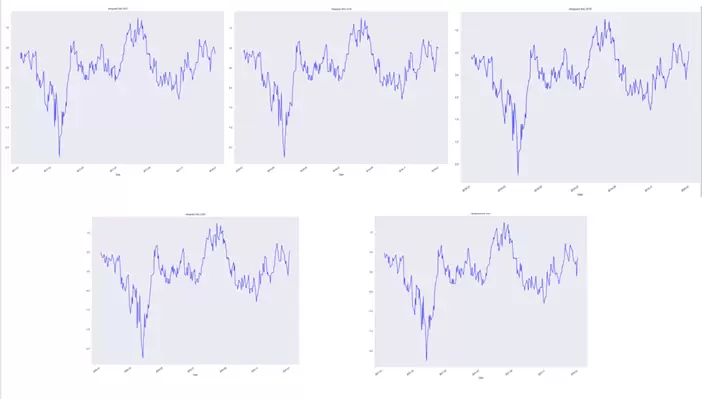
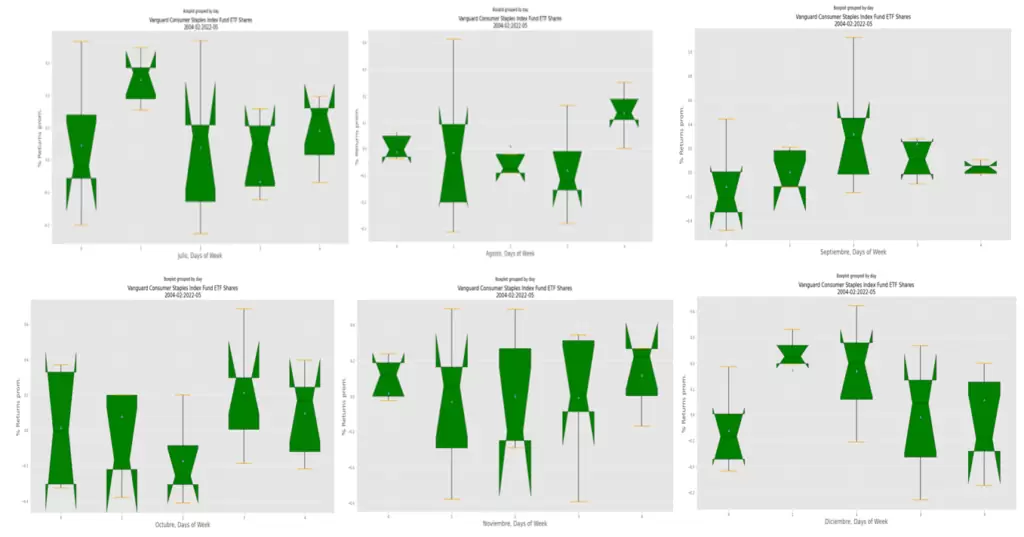
Pasamos ahora a analizar los intervalos medios del incremento de los rendimientos por días hábiles de negociación de cada mes.
# Mes de Enero:
returns_of_January = returns.loc[returns.index.month.isin([1])]
boxplot_group_day(returns_of_January)
plt.title(caso_boxplot, fontsize=16)
plt.xlabel("Enero, Days of Week", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
# Mes de Febrero:
returns_of_february = returns.loc[returns.index.month.isin([2])]
boxplot_group_day(returns_of_february)
plt.title(caso_boxplot, fontsize=16)
plt.xlabel("Febrero, Days", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
# Mes de Marzo:
returns_of_march = returns.loc[returns.index.month.isin([3])]
boxplot_group_day(returns_of_march)
plt.title(caso_boxplot, fontsize=16)
plt.xlabel("Marzo, Days of Week", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
# Mes de Abril:
returns_of_april = returns.loc[returns.index.month.isin([4])]
boxplot_group_day(returns_of_april)
plt.title(caso_boxplot, fontsize=16)
plt.xlabel("Abril, Days of Week", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
# Mes de Mayo:
returns_of_may = returns.loc[returns.index.month.isin([5])]
boxplot_group_day(returns_of_may)
plt.title(caso_boxplot, fontsize=16)
plt.xlabel("Mayo, Days of Week", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
# Mes de Junio:
returns_of_june = returns.loc[returns.index.month.isin([6])]
boxplot_group_day(returns_of_june)
plt.title(caso_boxplot, fontsize=16)
plt.xlabel("Junio, Days of Week", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
# Mes de Julio:
returns_of_July = returns.loc[returns.index.month.isin([7])]
boxplot_group_day(returns_of_July)
plt.title("Julio", fontsize=22)
plt.xlabel("Julio, Days of Week", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
# Mes de Agosto:
returns_of_august = returns.loc[returns.index.month.isin([8])]
boxplot_group_day(returns_of_august)
plt.title(caso_boxplot, fontsize=16)
plt.xlabel("Agosto, Days of Week", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
# Mes de Septiembre:
returns_of_september = returns.loc[returns.index.month.isin([9])]
boxplot_group_day(returns_of_september)
plt.title(caso_boxplot, fontsize=16)
plt.xlabel("Septiembre, Days of Week", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
# Mes de Octubre:
returns_of_octuber = returns.loc[returns.index.month.isin([10])]
boxplot_group_day(returns_of_octuber)
plt.title(caso_boxplot, fontsize=16)
plt.xlabel("Octubre, Days of Week", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
# Mes de Noviembre:
returns_of_november = returns.loc[returns.index.month.isin([11])]
boxplot_group_day(returns_of_november)
plt.title(caso_boxplot, fontsize=16)
plt.xlabel("Noviembre, Days of Week", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
# Mes de Diciembre:
returns_of_december = returns.loc[returns.index.month.isin([12])]
boxplot_group_day(returns_of_december)
plt.title(caso_boxplot, fontsize=16)
plt.xlabel("Diciembre, Days of Week", fontsize=18)
plt.ylabel("% Returns prom.", fontsize=18);
Los diferentes gráficos que resultan de ejecutar el código anterior serían los siguientes:
Veamos ahora algunas métricas generales de una estrategia basada en Buy & Hold para el activo subyacente. En primer lugar, calculamos la tasa de crecimiento anual compuesto y el resultado de comprar y mantener.
from scipy.stats import norm
Años = df["roc1"].count()/252
CAGR = (df["Close"].iloc[-1]/ df["Close"].iloc[0]) ** (1 / Años) - 1
print(50*"=")
print("> Tasa de Crecimiento Anual Compuesto:","%.6s" % (100*CAGR), "%")
print("> Buy & Hold:", "%.6s" % (100*((df["Close"].iloc[-1] - df["Close"].iloc[0])/
df["Close"].iloc[0])),"%")
# Calculamos el Máximo Drawdown
DD = pd.DataFrame({"Close": df["Close"],
"Previous Peak": Maximo_Anterior,
"Drawdown": df["drawdown"]})
print("> Máximo Drawdown Histórico:", "%.6s" % np.min(DD["Drawdown"]),"%")
# Obtenemos el promedio, desviación típica, máximo y mínimo valor y número de datos analizados:
print ("> Media Diaria;", "%.6s" % (df["roc1"].mean()),"%")
print ("> Desviación Típica Diaria:", "%.6s" % (df["roc1"]).std(ddof=1),"%")
print ("> Máxima Pérdida Diaria:", "%.6s" % (df["roc1"].min()),"%")
print ("> Máximo beneficio Diario", "%.6s" % (df["roc1"].max()),"%")
print ("> Días Analizados:", "%.6s" % df["roc1"].count())
print(50*"=")
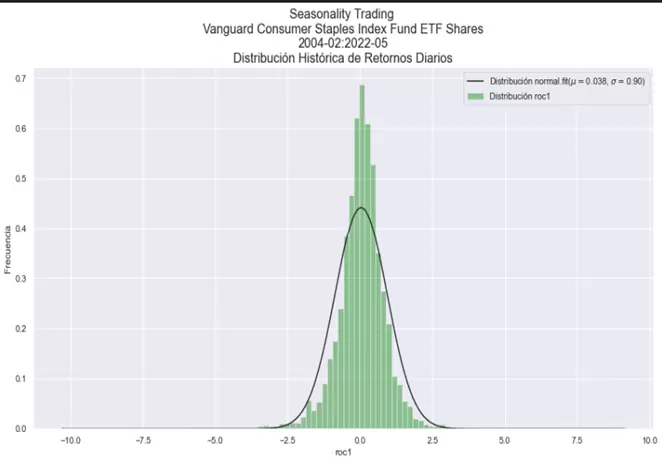
Analizamos la distribución de los rendimientos del activo:
import seaborn as sns
from scipy import stats
from scipy.stats import norm
# Eliminamos la primera fila del DF; contiene un valor NaN en el cálculo del roc1.
df = df.iloc[1:]
# Dibujamos en el histograma de frecuencias.
plt.figure(figsize=(15,8))
sns.set(color_codes = True)
axs = sns.distplot(df["roc1"], bins=100, kde=False, fit=stats.norm, color="green")
# Obtenemos los parámetros ajustados de la distribución normal utlizados por SNS
(mu, sigma) = stats.norm.fit(df["roc1"])
# Configuramos el título del gráfico, legendas y etiquetas.
plt.title(caso_distribucion, fontsize = 16)
plt.ylabel("Frecuencia")
plt.legend(["Distribución normal.fit($mu=${0:.2g}, $sigma=${1:.2f})".format(mu ,sigma),
"Distribución roc1"])
# Coeficiente de Asimetría y Curtosis de la Distribución.
print("> Coeficiente de Asimetría:", "%.6s" % df["roc1"].skew())
print("> Curtosis:", "%.6s" % df["roc1"].kurt())
print(50*"=")
# VaR Teórico obtenido a través de la distribución normal al 95% y 99% de confianza
mu = (df["roc1"].mean())
sigma = (df["roc1"]).std(ddof=1)
print("> VaR Modelo Gaussiano NC-95% :" , "%.6s" % (norm.ppf(0.05, mu, sigma)),"%")
print("> VaR Modelo Gaussiano NC-95.7% :" , "%.6s" % (norm.ppf(0.003, mu, sigma)),"%")
print("> VaR Modelo Gaussiano NC-99% :" , "%.6s" % (norm.ppf(0.01, mu, sigma)),"%")
# VaR Histórico al 95% y 99% de confianza.
print("> VaR Modelo Histórico NC-95% :" , "%.6s" % (np.percentile(df["roc1"],5)), "%")
print("> VaR Modelo Histórico NC-99% :" , "%.6s" % (np.percentile(df["roc1"],1)), "%")
print("> VaR Modelo Histórico NC-99.7% :" , "%.6s" % (np.percentile(df["roc1"],.3)), "%")
print(50*"=")
El aspecto de la distribución junto con sus estadísticos asociados son los siguientes:
Coeficiente de Asimetría: -0.344 Curtosis: 13.928 VaR Modelo Gaussiano NC-95% : -1.446 % VaR Modelo Gaussiano NC-95.7% : -2.441 % VaR Modelo Gaussiano NC-99% : -2.061 %
Los valores obtenidos en los apartados anteriores nos sirven para conocer cómo se distribuyen los rendimientos y cuánto se desvían de una distribución Normal. En particular, el coeficiente de asimetría (skewness) mide la asimetría de la distribución de los retornos sobre su media. Este valor puede ser positivo, negativo o neutro. En una distribución Normal el coeficiente de asimetría es 0 ya que ambas colas están simétricamente balanceadas. En nuestra distribución este valor es positivo lo cual indica que la cola derecha es más larga que la izquierda. Dicho de otro modo, en la cola derecha encontramos valores más alejados de la media que en la cola izquierda, lo cual en este caso particular es positivo.
Por su parte, la curtosis (kurtosis) nos indica en qué grado la distribución es más o menos apuntada que la Normal, y en qué medida las colas de la distribución difieren de las colas de una distribución Normal. En una distribución Normal, la curtosis tiene un valor de 3. En nuestra distribución este valor es superior, lo cual nos indica que es más apuntada que la Normal y que sus colas son más largas de lo que se espera en una distribución Normal. Dicho de otro modo, nos indica que nuestra distribución contiene valores que exceden las 3 desviaciones típicas de la media, las cuales no son excedidas con una probabilidad del 99.7% en una distribución Normal. Cuando la curtosis excede la normalidad se dice que la distribución es leptocúrtica.
El análisis de ambos coeficientes por tanto nos indican que la serie de rendimientos no se ajusta totalmente a la normalidad.
Asimismo, en el último apartado de las estadísticas podemos ver los valores para el VaR (Value at Risk) calculado de dos modos distintos: en el primer caso, se utiliza el modelo gaussiano, el cual asume que los rendimientos están normalmente distribuidos, mientras que en el segundo caso se utiliza el modelo basado en datos históricos, en el que se utiliza la distribución empírica, y en el que no se establecen supuestos sobre el tipo de distribución de la serie. En ambos casos se obtiene cuál es la peor pérdida esperada con un nivel de confianza del 95%, 99% y 99.7%.
Aquí se observa que con un nivel de confianza del 95% ambos métodos obtienen un valor muy similar. Sin embargo, al 99% y al 95.7% las diferencias son notables. En ambos casos el resultado esperado en el modelo empírico es peor que en el modelo gaussiano, lo cual nos confirma nuevamente que la cola izquierda de nuestra distribución es más larga que la de la Normal.
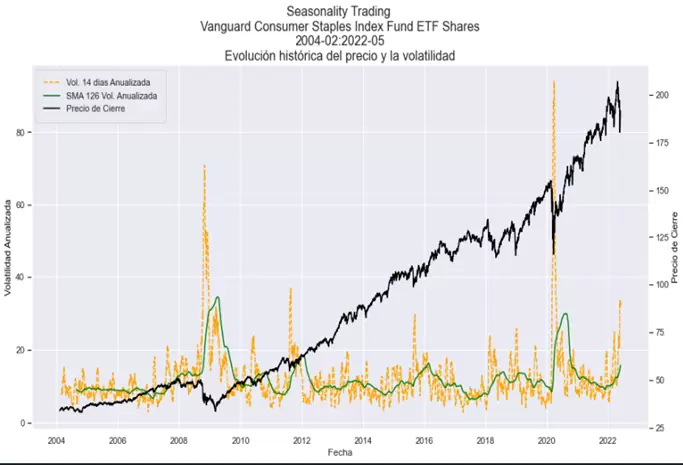
Vamos a analizar ahora la volatilidad histórica de nuestra serie temporal. Principalmente nos interesa conocer la evolución de la volatilidad durante todo el periodo. El código inferior nos sirve para crear un gráfico que muestra la evolución de los siguientes tres valores:
Volatilidad anualizada: desviación típica de los últimos 14 días multiplicada por la raíz cuadrada de 252.
Media aritmética sobre la volatilidad anualizada (SMA): muestra el promedio de los últimos 126 valores de la volatilidad anualizada.
Precio de cierre de ajustado.
Podemos obtener estos valores usando el siguiente código:
df["Volatilidad_Historica_14_Dias"] = df["roc1"].rolling(14).std()
df["Volatilidad_14_Dias_Anualizada"] = df["Volatilidad_Historica_14_Dias"]*(252**0.5)
df["SMA_126_Volatilidad_Anualizada"] = df["Volatilidad_14_Dias_Anualizada"].rolling(126).mean()
# 1. Creamos una figura y creamos un nuevo eje X e Y
fig, ax1 = plt.subplots(figsize=(15,8))
# 2.Creamos un nuevo eje. Aquí el eje X es invisible y el eje Y se sitúa en el lado opuesto del original.
ax2 = ax1.twinx()
# Creamos los objetos que queremos dibujar en los ejes ax1 y ax2
volatilityLine = ax1.plot(df["Volatilidad_14_Dias_Anualizada"], "orange", linestyle="--", label="Vol. 14 dias Anualizada")
smaLine = ax1.plot(df["SMA_126_Volatilidad_Anualizada"], "green", linestyle="-", label="SMA 126 Vol. Anualizada")
closeLine = ax2.plot(df["Close"], "black", label="Precio de Cierre")
# Título del Gráfico
plt.title(caso_volatilidad, fontsize=16)
# Etiquetas de los ejes x e y.
ax1.set_xlabel("Fecha")
ax1.set_ylabel("Volatilidad Anualizada", color="black")
ax2.set_ylabel("Precio de Cierre", color="black")
# Creamos una lista con los diferentes Plots que tengamos (Aquí tres)
plotLines = volatilityLine + smaLine + closeLine
#Creamos una nueva lista extrayendo las etiquetas de cada plot.
labels = [line.get_label() for line in plotLines]
#En la leyenda incluímos la lista de plots y las etiquetas de cada plot.
ax1.legend(plotLines, labels, loc="upper left", frameon=True, borderpad=1)
ax1.grid(True)
ax2.grid(False)
plt.show()
¡Sin duda una imagen vale más que mil palabras! En el gráfico que podemos ver a continuación se muestra la evolución histórica de la volatilidad anualizada, mostrando los distintos picos y valles producidos a lo largo del histórico, y su relación con los movimientos históricos del precio:
El siguiente bloque de instrucciones nos va a permitir analizar la volatilidad más a fondo. Comenzaremos obteniendo la volatilidad histórica para, seguidamente, localizar cuáles han sido el valor máximo y mínimo alcanzados históricamente, y registraremos las fechas en las que se han producido ambos valores.
Para completar el análisis también veremos si existe alguna relación entre la volatilidad y la dirección de la sesión. Para responder a esta pregunta calcularemos el rango medio porcentual de los días alcistas y bajistas de un modo independiente y, seguidamente, construiremos un ratio que comparará ambos valores para conocer la asimetría de la volatilidad.
# Volatilidad anualizada
VAM = (252**0.5)*(df["roc1"].std())
print("> Volatilidad Anualizada:" , "%.6s" % VAM, "%" )
# Obtenemos el valor mínimo y máximo de la volatilidad anualizada, así como las fechas en los que ambos valores son producidos.
Fecha_Minima_Volatilidad= df.Volatilidad_14_Dias_Anualizada[df.Volatilidad_14_Dias_Anualizada ==
df["Volatilidad_14_Dias_Anualizada"].min()].index.strftime("%Y-%m-%d").tolist()
Fecha_Maxima_Volatilidad= df.Volatilidad_14_Dias_Anualizada[df.Volatilidad_14_Dias_Anualizada ==
df["Volatilidad_14_Dias_Anualizada"].max()].index.strftime("%Y-%m-%d").tolist()
print ("> La Mínima Volatilidad Anualizada fue de", "%.6s" %
(df["Volatilidad_14_Dias_Anualizada"].min()),
"%", "registrada el", Fecha_Minima_Volatilidad[0])
print ("> La Máxima Volatilidad Anualizada fue de", "%.6s" %
(df["Volatilidad_14_Dias_Anualizada"].max()),
"%", "registrada el", Fecha_Maxima_Volatilidad[0])
El resultado del código anterior es el siguiente:
Volatilidad Anualizada: 14.324 % La Mínima Volatilidad Anualizada fue de 2.8194 % registrada el 2017-04-05 La Máxima Volatilidad Anualizada fue de 93.846 % registrada el 2020-03-26
Obtenemos también el promedio sobre el rango porcentual de los días negativos y de los días positivos, y el ratio entre ambos valores:
# Obtenemos el promedio sobre el rango porcentual de los días negativos.
df["DiasNegativos"] = np.where(df["roc1"] < 0, 100*(df["High"]-df["Low"])/df["Low"],0)
df_dias_negativos = df.loc[df["DiasNegativos"] != 0]
DN = df_dias_negativos["DiasNegativos"].mean()
print("> Rango Medio días Negativos:", "%.4s" % DN, "%")
# Obtenemos el promedio del rango porcentual de los días positivos.
df["DiasPositivos"] = np.where(df["roc1"] > 0, 100*(df["High"]-df["Low"])/df["Low"],0)
df_dias_positivos = df.loc[df["DiasPositivos"] != 0]
DP = df_dias_positivos["DiasPositivos"].mean()
print("> Rango Medio días Positivos:", "%.4s" % DP, "%")
# Calculamos el ratio del rango entre los días positivos y negativos.
print("> Ratio RDN/RDP", "%.4s"%(DN/DP), "%")
El resultado del script es el siguiente:
Rango Medio días Negativos: 1.12 % Rango Medio días Positivos: 0.90 % Ratio RDN/RDP 1.23 %
Conclusión
En este artículo hemos visto diferentes bloques de código que nos permitirán analizar cualquier serie financiera desde un punto de vista cuantitativo, lo cual nos permitirá caracterizar desde un punto de vista estadístico el comportamiento de la serie. Los resultados obtenidos nos ayudarán a desarrollar y contextualizar nuestras estrategias de trading.
En el próximo artículo, pasaremos a examinar el código necesario para extraer toda la información de tipo estacional sobre la cual podremos construir nuestra estrategia de trading estacional.